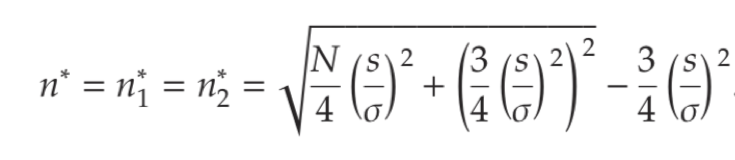הרבה מאוד זמן לא כתבתי בבלוג הזה, אבל מדי פעם מדגדג לי. חשבתי שאולי הגיע הזמן להשוות מעט בין העסקים בישראל ובארה״ב. אחרי 13 שנה אולי יש לי אבחנות רלוונטיות (ואולי סתם אנקדוטות).
המטרה של הפוסטים האלו היא לא להשוות בגישת ״הכל בארה״ב יותר טוב וכמה רע בארץ״ (יום אחד אכתוב על מערכת הבריאות האמריקאית המזעזעת), אלא יותר לנסות לאבחן מדוע הסביבה העסקית בארה״ב כל-כך דינמית ומצליחה, ומה אפשר ללמוד ממנה. בסדרת הפוסטים אנסה גם לתת אבחנות (ועצות רחמנא ליצלן) שיכולות לסייע לעסקים קטנים וגדולים.
אחד הדברים הבולטים בארה״ב הוא תכנון מערכות להתמודדות עם מסה גדולה של אנשים ובמינימום התערבות אנושית, בעיקר בתחום מתן אינפורמציה ללקוחות. כל פעם שאני בא לבקר בישראל אני מוצא את עצמי מדבר עם המון אנשים כדי לברר מידע. מידע פשוט כמו שעות פתיחה של סניף מסוים והאם יש בו פריט במלאי, איפה ניתן לחנות ליד מסעדה, או איך משלמים בתחבורה ציבורית.
במרבית המקרים זה נגמר בלשאול חבר.ה (או שניים), ששואלים אחרים, ובסוף מתקבלת תשובה שאף פעם לא לגמרי רשמית. לחילופין, אני צריך להתקשר ולדבר עם מישהו, שלפעמים יודע את התשובה, ולפעמים לא. בהרבה מקרים, ניסיון להסתמך על האתר או האפליקציה של נותן השירות מבהירים שאין להם אתר או אפליקציה, או שהפעם האחרונה שעדכנו אותם הייתה בשנת 2015.
בתקופת הקורונה זה בלט מאוד כשהצלחנו לבוא לבקר בישראל והיה מאוד קשה להבין מה צריך לעשות, איך לעשות את זה ומתי.
הבעיה העיקרית היא שספקי השירותים (בעלי העסקים, העובדים וכו׳) בד״כ מתקשים להבין את הבעיה של הלקוח כי יש להם את המידע ולכן התשובה ברורה להם. בנוסף, גם אם ירצו לספק את המידע לציבור, הם לא ממש יודעים למי לדווח או איך לעשות את זה.
כדי שזה לא יהיה פוסט תאורטי ומשעמם, הנה דוגמא (קצת ישנה אך רלוונטית).
לפני הרבה שנים, כשהייתי המדריך הראשי של תכנית תלפיות, הייתי אחראי לתקופה קצרה על חלק מתהליך המיון לתכנית. מדובר בימים שבהם לא היו סמארטפונים, ואנשים עדיין שלחו פקסים והתקשרו בטלפונים כדי לברר מידע. לתכנית היה אתר אינטרנט עם מעט פרטים (טופס שניתן למלא כדי לבקש להתמיין לתכנית, מספר טלפון ופקס של משרד המיונים, וכתובת להגעה לימי המיון).
הייתה לנו קבוצת חיילים שירותית ואיכותית מאוד שהיו חלק מצוות תפעול מערך המיונים, תפקידם העיקרי היה לסייע בימי המיונים (חלוקת מבחנים, סריקתם לבדיקה, שליחת מכתבי זימון וכו׳). הם היו נפלאים, נחמדים ומאוד רצו לעזור לכל מי שנדרש לעזרה. הבעיה הייתה שהם היו עמוסים בתקופת המיון עד אין קץ במענה לטלפונים (של הורים ומלש״בים), ובמקביל היו צריכים לנהל את ימי המיונים עצמם.
הטלפונים לא הפסיקו לצלצל, הפקסים עם השאלות זרמו, והחיילים --- היו מסכנים.
הפתרון המקובל של מנהלים (אז וגם היום) הוא לבקש עוד כח אדם, עוד קווי טלפון ועוד משאבים - הרי הביקוש (למענה לטלפון) עולה על ההיצע, ולכן הפתרון הוא להגדיל את ההיצע.
לצערנו (אבל בדיעבד לטובתנו), לא אישרו לנו תוספת כח אדם, ונאלצנו לפתור את הבעיה בעצמנו. הדבר הראשון שעשינו הוא להקים פורום אינטרנטי באתר התכנית בו מלש״בים יכלו לשאול שאלות וצוות התכנית (וגם חלק מהחניכים) יכלו לענות עליהן. חילקנו את הפורום לנושאים, ומהר מאוד הוא החל להתמלא בתוכן.
היו שם שאלות מגוונות מאוד, החל מ״איך מבקשים להתמיין לתלפיות״ (שולחים פקס או דואר עם פרטים בסיסיים, או מדברים עם מורה/יועץ בבי״ס), ״מה להביא ליום המיון״ (שתייה ואוכל), ו״איך להתכונן למיון״ (אין מה להתכונן).
היו גם המון שאלות חשובות אחרות כמו ״האם בנות יכולות להתקבל לתלפיות״ (כן, כבר מעל 30 שנה), ״אילו תפקידים מוצעים לבוגרים״ ועוד.
היו כמה יתרונות לפורום הזה:
מכיוון שחניכים שולבו במענה לשאלות (וגם ידעו הרבה יותר פרטים מעניינים על התכנית מסגל המיון), התשובות בפורום נכנסו לעומק וסיפקו מידע שהיה מאוד קשה לקבל בטלפון.
גוגל התחיל לאנדקס את התוצאות ואנשים שהקלידו שאלה בגוגל הגיעו ישר לתשובה הרלוונטית.
היו משתמשים בפורום שהפכו למעין ״סופר יוזר״ והתחילו בעצמם לענות על השאלות, כי הרבה שאלות חזרו על עצמן.
אבל לפורום הייתה בעיה - הרבה מאוד שאלות חזרו על עצמן -- מרבית האנשים לא חיפשו תשובות לשאלות קודמות -- הרבה יותר קל היה לשאול שאלה חדשה. בנוסף, כמות הטלפונים לא קטנה מאוד -- אנשים לא סמכו לגמרי על התשובות בפורום (כי מי שעונה הוא חניך, או משתמש אחר), ובאופן כללי העדיפו לוודא.
הפתרון השני היה לעבור על כל תכני הפורום ולייצר רשימת ״שאלות נפוצות״. בערך 90 אחוז מהתוכן (גם בפורום וגם בטלפון) חזר על עצמו. אותן שאלות בדיוק, וסה״כ היו בערך 20 שאלות. כתבנו תשובה רשמית לשאלות (ש:איזה קו אוטובוס מגיע לגבעת רם? ת: 28). ופרסמנו אותן בעמוד שאלות ותשובות נפוצות (מה שנקרא FAQ). האפקט היה מדהים. תוך שבוע נפח הטלפונים למשרדי המיון קטן בכמעט חצי, ובאיזשהו שלב, גם מי שענה לטלפון ידע ברוב המקרים פשוט להפנות לדף האינטרנט.
מחסור במידע אצל לקוחות נקרא בשפה האקדמית חיכוך מידע (Information Friction), וחיכוך הוא גורם שמקטין את כמות העסקאות והעסקים שמבוצעות. כאשר לקוח לא יודע פריט מידע מסוים, או לא בטוח ב״חוקי המשחק״, או צריך לדבר עם מישהו כדי לברר פרטים, בהרבה מקרים הוא יעדיף לוותר על השירות או ללכת למתחרה.
ככלל אצבע, עדיף תמיד לספק יותר מדי מידע מאשר פחות מדי מידע. זה מייצר אמון בקרב הלקוחות, ומסיר חיכוכים וחסמים לעסקה.
דוגמא נפוצה בישראל היא אי-פרסום מחירים של מוצרים, וספציפית מחירי שכירות, מחירי רכב ומחירי בתים למכירה. לא מעט נתקלתי במודעות שמפרסמות דירה להשכרה (בפייסבוק לדוגמא) ולא מציינות את שכר הדירה. אם קוראים את התגובות לפוסט, בדרך-כלל נשאלת אותה שאלה 90 אחוזים מהזמן -- מה שכר הדירה? הרי זה הדבר הראשון שמישהו ירצה לדעת לפני שישקול לשכור דירה. ובמרבית המקרים אני נתקל במפרסם הפוסט שעונה ״שלחתי לך בפרטי״, או ״תתקשר ואענה לך״.
והאמת היא שאני לא מבין את המטרה. אם המטרה היא שיהיה פחות ביקוש לדירה, הרי בפירוש מפרסם הפוסט מצליח בכך, אבל אם המטרה היא להקטין חיכוכים (עסקיים) בביצוע העסקה, הרי תמיד רצוי לפרסם מחיר למוצר. כששאלתי אנשים מדוע הם לא מפרסמים מחיר, חלק אמרו לי ״כך נהוג״ (אז מה?), וחלק ענו לי ״ככה אוכל לעשות משא ומתן ואולי לקבל עסקה טובה יותר״. האינטואיציה הזו היא מוטעית מאוד...
הקונספט של מחיר שמפורסם על גבי המוצר (תגית מחיר) הוא חדש יחסית ובן כ - 160 שנה. הוא הומצא על ידי ג׳ון וונהמייקר (John Wanamaker) שהקים את אחת מחנויות הכלבו הראשונות בהיסטוריה (והייתה בפילדלפיה). וונהמייקר הבין שאם כל לקוח צריך למצוא מוכר שיאמר לו מה המחיר של כל מוצר, הוא יצטרך אינסוף מוכרים, והם יתעסקו בעיקר באספקת מידע די סטדנרטי במקום במתן שירות ומכירת מוצרים. המוכרים שהיו עסוקים לא באמת הציעו מחיר שונה לכל לקוח (או בכלל ידעו איך לתמחר בצורה שונה), ולכן לא היה ערך ליכולת המיקוח התאורטית שלהם.
אם העסק שלכם, הצוות שלכם או ספק השירות שלכם מתעסק כל היום במתן מידע שניתן לספק בעזרת מענה אוטומטי, אתר באינטרנט או אפלקיציה, אני מציע מאוד להשקיע בכך זמן. מעט מאוד עבודה יכולה לייצר שירות לקוחות טוב יותר, אמון מוגבר בין נותן השירות ללקוח, ובאופן כללי, חוויה עסקית טובה יותר וריבוי עסקאות נטולות חיכוך.
יש לכם דוגמאות נוספות לחסור במידע שמנע או מונע מכם לקנות מוצר או לקבל שירות? האם יש מקרים שבהם העדפתם מתחרה, גם אם היה יקר יותר, רק בגלל הסיפור הזה? אם כן, אשמח לדוגמאות בתגובות...
Imagine that you ran an A/B test using two variations of a webpage and measured their conversion rate. At the end of the experiment, version A has a higher conversion rate than B, but the difference is not statistically significant. What do you do?
I often ask students and executives this question, and receive one of two responses:
Continue to run the test until it shows statistical significance (Oh dear...don’t do that, unless you really know what you’re doing).
Pick version A even if the result is not significant.
The immediate follow-up question is: “If you pick the best performing version anyway if the results are not significant, why test for significance at all?”
The TL;DR answer is that you shouldn’t test for significance if you want to maximize your profits using A/B tests. You should design your experiment (and sample size) to detect large effects, and not worry too much about making mistakes when A is not too different from B. In this blog post I’ll explain the main ideas Elea McDonnell Feit and I developed in our recent paper Test & Roll: Profit-Maximizing A/B Tests. We used these insights to derive a new experimental design and sample size formula for A/B tests which yields much higher profits (and much shorter experiments) than using traditional hypothesis tests.
What is the goal of an A/B test?
When people run an A/B test, they usually have a goal in mind. That goal might read something like “Run a test comparing A and B. Then pick the version that performs the best”.
Hypothesis tests, in contrast, were designed by statisticians to answer the question “Can we confidently say that version A is different than version B?”. That means that hypothesis tests focus on not making the mistake of claiming that A is different than B when they are not (what is known as a Type I error).
But for profit maximizing A/B testers, this mistake has no consequence -- suppose you believe that A is better than B (as the test result shows), but in reality this is all noise and A performs the same as B. By choosing to move forward with version A, you lose nothing. The hypothesis test focused you too much on detecting very small effects.
This focus usually results in extremely large recommended sample sizes. Often much larger than the population available for a test. But in tactical A/B tests (which we call a “Test & Roll”), a firm often wants to run a quick test on a small population (Test stage), and then deploy one variation on the remaining population which was left out of the test (Roll stage). If the population is not extremely large, or if the effects are small on average (both of which are common cases), using hypothesis tests is too conservative and lowers the profit of the firm, because too much effort is wasted in the test stage.
How to run a Test & Roll?
In its simplest version, a Test & Roll has two stages. In the test stage the data scientist runs an A/B test on some small population of size n out of N potential customers. Once the experiment is completed, the data scientist deploys the version with the highest conversion rate on the remaining (N-n) customers. Pretty simple, eh? There are no hypothesis tests involved.
How large should the test population n be?
In the paper we develop a new sample size formula:
In this formula, N is the total size of the available population (for the Test and the Roll together). ???? measures the variation in performance across different treatments, which a data scientist can estimate from results from previous experiments. s is the expected standard deviation of the data within the experiment, which again can be estimated from past experiments. In the paper we give three examples of how to find ???? and s, for offline catalog holdout tests, website A/B tests and online advertising tests.
To make using the Test & Roll formula easy, and to allow you to compare the expected benefit of Test & Roll (before deploying it), we created a nifty calculator at http://testandroll.com.
How well does Test & Roll perform?
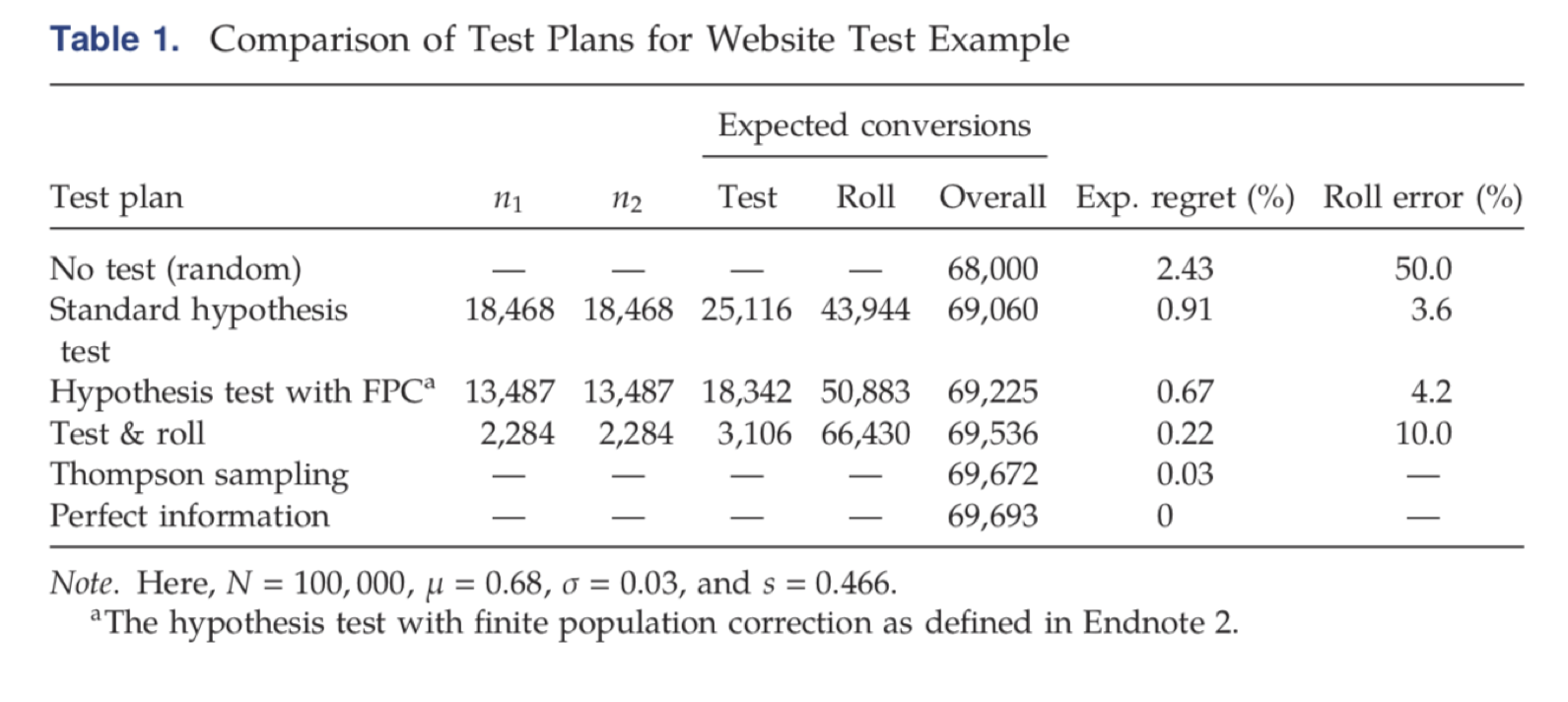
This table, adapted from the paper, shows how well Test & Roll performs compared to hypothesis testing, to the optimal possible allocation (assuming the data scientist actually knows which treatment is better without the test), and Thompson sampling, which is a variant of a solution to the multi-armed bandit problem. The comparison is done on data from a few thousand website A/B tests:
To compare algorithms, we usually use a measure called “Regret”, which (roughly) answers the question: “How well does this algorithm perform compared to the theoretical optimum, where we know all the information in hindsight”. The table shows that Test & Roll has about one quarter of the regret of a standard hypothesis test, and not much higher regret than the more sophisticated (and complex) multi-armed bandit.
This result repeated itself in all of our applications, and even when we tried to “break” Test & Roll and find cases where it performs much worse than a multi-armed bandit, it was pretty hard to do. If you’re not familiar with multi-armed bandits, it is basically a fully dynamic approach (not only two stages, but many stages) to maximizing profit while learning from the data of previous customers.
Why does Test & Roll work?
The intuition behind Test & Roll is pretty neat. What Test & Roll does is create a trade-off between the test and the roll stages. If a lot of users are allocated to the test stage, the algorithm will pick the best performing variation with very high confidence, but then in the roll stage, there wouldn’t be enough customers left to exploit the fact that we know which variation is the best.
If not many users are used for testing in the test stage, we get the opposite - the algorithm will often make mistakes, recommending to pick the lesser performing variation.
But this is the crux of the magic - when the treatment effect (the difference between A and B) is large, the algorithm will pick the best variation with high confidence even with a small sample of users in the test stage. In other words, even very small tests are good at finding large effects, and the benefit from them is very large.
And what about the mistakes from smaller treatment effects? In that case the damage for profit is negligible. Focusing on large effects allows the data scientist to quickly find these “much better” variations, and move on to the roll stage.
This behavior can be observed in Table 1 above. Although Test & Roll picks the worst performing variation in 10% of the cases (compared to only 3.6% mistakes for standard hypothesis testing), it does so primarily when the differences are small, and in the end, these mistakes don’t matter much.
What else can Test & Roll do?
Test & Roll can be adapted to cases in which the data scientist has some prior information that one variation is probably better than another, or to cases where these is a “default” variation, and only if the new one performs much better the switch is made.
Plugging this information into the complete Test & Roll formula (which appears in the paper) yields asymmetric tests, where one variation gets allocated more users in the test stage than the other, to gain even more improvement in the profit.
Test & Roll can also be adapted to cases where the data is not normally distributed (or can’t be made normal through a transformation). For example, if the experiment tests 0/1 conversions, and the data is not very large, a numerical approach can be used to design Test & Roll experiments for binary data.
Summary
Test & Roll is designed for quick, tactical A/B tests (which many companies run all the time). Using the sample size formula we derived, we expect companies to achieve higher profit than using hypothesis tests to design their experiments, and we expect them to achieve these profits faster. Test & Roll will often recommend a dramatically smaller sample size for your experiments, and will make decision making clear and transparent.
I’d like to emphasize that Test & Roll is not a panacea for all your experimental needs. When the cost of a mistake is substantial even for small mistakes (for example, in clinical trials where life might be lost), hypothesis tests are the way to go. In other cases, where the question is to really determine behavior (“is A really different than B?”), hypothesis tests are again warranted. The idea behind Test & Roll, and other new approaches to experimentation, is to match the technique used to the decision that is being made.
Recently, Chris Said wrote an excellent series of blog posts where he developed an approach similar to ours (using the same principles) where instead of using a finite test & deploy population, the data scientist has a trade-off between the profit they want to achieve, and the amount of time it will take them to run the test. Quite neatly, Chris arrives at a very similar sample size formula to ours. I think it is very cool that two seemingly different approaches reach a very similar conclusion.
Finally, I tried to avoid going into much of the mathy details behind Test & Roll, but I highly recommend reading the paper if you’re interested in them. It is pretty short, and we made a big effort to be as clear and transparent as possible about the benefits and limitations of Test & Roll.
In case you have questions, comments, feedback etc., please do not hesitate to leave a comment, or contact me and Elea. Even better, if you would like to collaborate with us on developing the next phase of A/B testing techniques, we would love to hear from you!
Yesterday my phone started buzzing more than usual with Twitter updates. Turns out our working paper on A/B testing has attracted the attention of a few notable academics on Twitter. Again.
I'm not sure what prompted this new wave of attention. Perhaps it was the fact we uploaded a new version to SSRN. Perhaps it is those end of year summaries I see people making.
One tweet, however, from Ron Kohavi, Microsoft VP of Analysis and Experimentation, was interesting:
Claim of widespread p-hacking sensationalized in paper suffering lack of external validity on two axes: skew due to massive selection bias and time bias.
"Oh, dear", I was thinking to myself. Kohavi is one of the stars of the A/B testing world. What's up with that?
I will address Kohavi's points below, to the best of my understanding of the issues he raised. I am not sure what prompted this "sensational tweet", but I very much welcome feedback about our paper. I hear that email still works as a technology, though.
TL;DR: Don't be that person that doesn't read an entire post because it'll take you 3 minutes. You'll end up like those who make judgement calls about papers based on Tweets by other people:
1. "Selection bias" - Kohavi says "Optimizely’s product was designed for the uninformed, so there is massive selection bias." By "selection bias" Kohavi means that the sample of people in our data who use the platform to run experiments is not representative of the behavior of "normal" ("informed") experimenters.
The fact is that Optimizely is the largest (as far as I can tell) 3rd party A/B testing provider, which is why we worked very hard to convince them to share data with us. The median experimenter in our dataset had run 184 experiments before we collected our data, and there are over 900 of them in our dataset. The platform had over 9,000 experiments started on it in the data collection window. This is more than 6 times higher than what Kohavi mentions they ran on Bing in roughly the same time period (though I am sure Bing.com experiments are larger in sample size).
A study that analyzes experimenter behavior in the wild, on a widely used A/B testing platform, has a lot of external validity about how businesses behave when they experiment. The findings might not apply to Microsoft, or Facebook, but these companies do not need our help in analyzing their internal experiments. In contrast, deriving conclusions from studies about experiments that are run internally at Microsoft or Facebook probably apply less to a "normal" business.
2. "Selection bias" (2) - Even "uninformed" experimenters should have noticed if, experiment after experiment, their decisions result in lower profit. This is basically the rational decision maker assumption we often make in our analysis. We wanted to test it, and we found interesting results.
3. "Selection bias" (3) - Kohavi claims (or assumes) that informed decision makers do not make such mistakes.
In contrast to just claiming otherwise, our paper actually cites many references that show this is incorrect (medical doctors, informed academics and even statisticians make mistakes in interpreting results).
So to summarize - is our dataset representative? It is, if you're the type of A/B tester that runs experiments similar to those used on the platform we got the data from. Luckily, it applies to many if not most businesses.
4. "Time Bias" - Kohavi says "The paper’s external validity across time is therefore weak: most businesses who use A/B testing in the last 2-3 years are aware of the issue, and Optimizely's software improved."
I am not sure where the "most" comes from in this sentence and what data supports this claim. Many businesses I encounter (and I encounter a wide variety of businesses as a business school professor) are not aware of this issue, or are aware but not sure of the details, or are not sure how to resolve it, etc.
Optimizely's software has indeed improved, but was the problem resolved? Well, it depends on what problem we're talking about.
For this, I recommend that you read the paper and not just the abstract, but this is the gist of it: Optimizely's software in 2014 notified users they can stop an A/B test when the confidence metric was above 95% or below 5%.
However, and this is a big HOWEVER, this is not where we found experimenters stopped their experiments. Many of them stopped when they reached 90% confidence. So the problem that people might have tried to solve since 2014 might not have been the relevant problem to solve.
When I invest time and money in solving a problem, I prefer to know that the problem exists, and what the negative consequences of the problem are. This is what our paper tries to achieve. We simply ask: "Was there a problem, and if there was, how prevalent was it and what consequences did it have".
We then just report our findings (and how we found them). It would also have been interesting if we found no p-hacking and low FDRs, and it was also interesting when we found there was p-hacking and that it did inflate the FDR. Both findings are interesting.
5. "Sensationalized" - Kohavi uses words such as "widespread", "sensationalized", "massive" and "bias" in his text. By using "bias" he actually hints that our results are biased (although what he actually says is that the results are probably correct, just not generalizable).
The paper's abstract is pretty straightforward. It describes the findings of the paper (like any other abstract), and does not use any superlatives. We use very measured language in the paper, and our conclusions very carefully explain what we believe are limitations to conclusions from the data. We have never made any attempt to "sensationalize" the paper. We presented it at conferences, submitted it to peer review, did a standard Wharton podcast about it, etc. Nothing fancy or unique.
So on this point, I don't have a good answer. I'm not sure why Kohavi thinks our paper is sensational. Maybe he means "sensationally interesting"? 🙂
===
To summarize, what do we actually do in the paper? We test a tradeoff.
On one hand, experimenters should want to avoid false discoveries. It will lower their profits. They should notice it pretty quickly if they run many experiments. On the other hand, the platform was designed in a way that allows naive experimenters to make mistakes.
We went about seeing which one prevails. It turns out that mistakes prevailed (sometimes) but not where expected, and not in the form assumed.
It's been almost two years since I wrote a post (busy times, I guess), and even longer since I wrote in English.
Nonetheless, I thought this topic may be of interest to readers of more than just Hebrew, so here goes...
One of the most popular posts on my site is a post in Hebrew about how freelancers often miscalculate their hourly earnings when they use their salary as an employee as a benchmark. Most freelancers are just unaware of the full costs of the benefits an employer pays for them, and as a result effectively take a pay-cut when they agree to become freelancers.
Today I'll write about something slightly different (but related) - advising startups and receiving equity as compensation.
My colleagues and I are sometimes approached to help companies in their earlier stages, and once in a while I get asked about compensation for this type of engagement. Since many of these companies cannot afford to pay using cash, equity in the form of stock options or common stock is often offered.
When I asked around among my friends once, I was referred to an agreement called FAST (short for "Founder / Advisor Standard Template") developed by the Founder's Institute as a benchmark for how to structure these agreements as well as a guidance about the equity compensation an advisor should receive.
Over time, I encountered this agreement more and more, which is why I decided to write this post analyzing the agreement as well as the compensation from an advisor's point of view.
I also asked the awesome Jonathan Raz from Raz, Ordan Law Offices for comments on the legal aspects of the contract which I will cover in a later post, and I brought up my spreadsheet for the financial part.
The question I am trying to answer is simple - if one engages as an advisor to a company and receives equity at such an early stage, how much is this equity worth in expectation?Given the time commitment suggested by the FAST agreement, what is the equivalent hourly rate an advisor using FAST is receiving?
I am putting aside, of course, other motives for helping companies such as paying it forward, enjoying the challenge and working with founders, and of course the immersive experience of the startup culture. At Wharton, for example, I often meet with entrepreneurs and students to contribute from our knowledge and experience.
To answer this question, I needed to estimate a few things:
What is the expected value of the equity given to the advisor at each stage?
What is the probability of a company actually having a successful exit at each stage?
What is the expected time commitment an advisor will have until the company's exit?
Answering these questions required collecting some data, and making quite a few assumptions. The interesting part is that the answer to "I have XXX shares in a company after round A, what is the expected value of these shares going forward?" is not publicly available, although it may be very relevant to any startup employee, consultant and advisor. The Google Sheet attached to this post may therefore also be useful to any person holding startup equity.
One point to note is that by "expected value", I mean the average over all companies, and not specifically for one company. That means that my analysis is probably more accurate for people who have small equity stakes in many companies, in which case the law of large numbers will kick in and the average value will actually be close to the expectation.
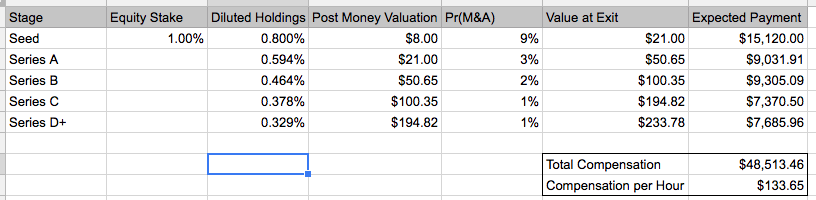
Suppose (using the FAST agreement) that you are an expert in a pre-seed stage company ("Idea Stage"). In that case the agreement guides that 1% of the company should be given for a time commitment of 20 hours a month, with two years of vesting.
What will be the value of this 1% when (and if) the company exits?
The first stage is to calculate the share of the company you will own after each funding round. In other words, we want to know how diluted your stake becomes with each round. All the data used for the analysis appears in this publicly available Google Sheet (it ain't beautiful, but it works).
This is a summarized version:
Using the benchmarks published by PitchBook's VC Valuations Report ((I used the annual 2016 values)), we can use the data for percentage acquired by investors at each round to calculate the diluted holdings of the advisors.
This value appears in the "Diluted Holdings" column of the table.
Next, I make the assumption that if a company exits prior to a specific round (for example, they exit after seed but before round A) then their exit value is as high as the post-money valuation of the next round.
I made this assumption for the following reasons:
I assumed that if a company could continue to grow quickly it would have raised a round and not exited, so probably it couldn't have reached the valuation for the next round with room to grow.
It makes life easy. 🙂
It was hard to find exit values for companies (conditional on the round they raised).
I think this may actually be an overestimate of the exit value, but that's always debatable. One value I didn't have is the exit value after a company raised a D round. I assumed the exit value is 20% higher. This was the return multiple reported by Pitchbook for late stage investors, and in addition these investors typically have a short time horizon for exit, so 20% made sense to me.
The values for this info appear in the column "Post Money Valuation".
After we know how much the advisor holds after each round and how much the company is worth, we need to know what the probabilities of exit and continuing to the next rounds are.
Most companies never reach an exit, or continue to the next round, as illustrated in the data in this Techcrunch post:
Unfortunately the graphs in the post were not published with the raw data (or even the graph numbers), so I had to eyeball the values using the image.
The column called Pr(M&A) gives the exit probability of a company at each stage. Those sum up to 16%, the total amount in the graph. Although about 40% of companies continue from the seed stage to round A (for example), the majority of them never have a positive exit.
One caveat is that the article doesn't mention how many companies in the dataset are still alive (and may still have an exit in the future) when the article was written. The article used data from 2003-2013 and was written in 2017, so I assume most companies have either exited or are dead by now.
Finally, we want to multiply the diluted holdings of an investor, the post-money valuation (at exit) and the probability of exit, and we receive the Expected Payment at each stage.
Summing it all up, we receive the expected value of about $50k for an expert advisor, contributing 20 hours per month for 2 years, and receiving 1% at the early stage of the company.
The final step was to estimate the amount of time an advisor is expected to spend with an "average" company before it either dies or has an exit.
I again used the data from the TechCrunch article (the image above doesn't contain the columns, but the Google Sheet does) to calculate that the expected amount of hours an advisor will spend in the 2 years of their vesting period will be about 363 hours (approx. 2 months of work in Israeli terms). This again may be an underestimate, since if a company actually has an exit, the advisor will probably spend with it at least 2 years.
This yields an average compensation of $133 per hour, which of course will be coming mostly from a few firms with large exits and most other firms will return nothing.
An hourly (freelance) rate of $133 in the U.S. is equivalent to an annual (employee) salary of around $165k (using this calculator and deducting 15% self employment tax).
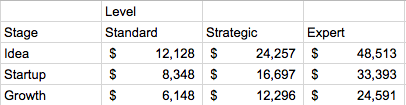
The following table summarizes the total expected compensation for each company stage and advising level suggested by the agreement:
Interestingly, the effective hourly rates are the same for all advising levels (Expert, Strategic, Standard), but do change by the stage of the companies. At the idea stage the effective rate is about $133 an hour. At the startup stage it is about $106 an hour, and at the the growth stage it goes down to $93 an hour.
So there you have it - the effective expected compensation and hourly rates of the FAST agreement. In the next post I will write about the legal details in the agreement, or as my friend Jonathan put it, "it is missing some key parts".
If you'd like to receive an update when the post gets published, be sure to enroll to the email updates from the blog.
הפוסט הקודם שלי על מחירי דירות בישראל נקרא ע״י קרוב ל - 2000 איש, וייצר לא מעט תגובות (״אין סיכוי שמחירי הדירות בישראל לא עלו״). בסיומו הבטחתי שאסביר את הטענה שלי ביתר פירוט, אבל מכיוון שאני עדיין אוסף נתונים, החלטתי לכתוב פוסט על תופעה די מוזרה (לדעתי) שעולה הרבה כסף לאזרחים בישראל.
כמה זה ״הרבה״? חישוב שלי מראה שמאז שנת 2008 מדובר ב 1.6 מיליארד ש״ח לערך.
כן, אמרתי מילארד ושש מאות מיליון ש״ח.
כשמדברים על ״מנגנון השוק״ ו״כשל שוק״ הרבה פעמים מתייחסים לצד ההיצע - לחברות שמספקות מוצרים ושירותים לציבור. לכן בד״כ אומרים שיש כשל שוק, למשל, כשנוצר מונופול שיכול להעלות מחירים של מוצרים.
לפעמים אומרים שיש כשל שוק כי יש רגולציה מגבילה - נניח בישראל טוענים שמאוד קשה לפתוח בנק חדש, ולכן הבנקים הקיימים יכולים להשית עלויות גבוהות על הציבור.
לפעמים אומרים שיש כשל שוק בגלל פערי מידע בין היצרן לצרכן - אם נניח שיש מוצר מאוד מורכב, וליצרנים יש מידע על האיכות של המוצר שלצרכנים אין את הכלים להעריך אותו, אז היצרן יכול ״לעבוד״ על הצרכנים ולגבות מהם מחירים גבוהים.
מעטים המקרים בהם מדברים על כשל שוק מצד הביקוש - מצד הצרכנים. בעקרון הטיעון הוא כזה: ״אם השוק חופשי ותחרותי, ולכולם יש מידע מספיק, אז הצרכנים יבחרו את המוצרים הכי טובים עבורם״.
בפוסט הזה אנסה להראות שני מוצרים בישראל שקיים לגביהם הרבה מידע, השוק יחסית תחרותי, קל לעבור ביניהם, ועדיין הנתונים מראים שייתכן והצרכנים קונים בהרבה מקרים את המוצר הנחות יותר, ובמחיר גבוה יותר.
אני זהיר בקביעה שלי ולא אומר ״הצרכנים בטוח טועים״, כי תמיד יש הסברים נוספים, אבל זו בהחלט תופעה שקשה להסביר לדעתי.
כדי להסביר את התופעה, אתחיל באנלוגיה.
נניח שכל כמה שנים אתם רוכשים רכב חדש, ובמשך שנים אתם קונים בדיוק את דגם X האהוב עליכם של יצרן מסוים.
כל חמש שנים אתם קונים את הגרסה החדשה של דגם X.
יום אחד בא אליכם סוכן המכירות ואומר לכם שיש גם את דגם X, כמו שאתם רגילים, אבל יש דגם חדש ששמו Y.
הוא מיוצר ע״י אותו יצרן, והוא בדיוק אותו הדגם, רק הוסיפו לו עוד כריות אוויר לשם הבטיחות, והמנוע שלו טיפה יותר טוב.
לרכב יש את אותם ביצועים, ואותם נתונים, ואותו גודל והכל בדיוק אותו דבר.
מעבר לכך, אומר לכם הסוכן, דגם Y זול יותר מדגם X.
נניח שאני לא עובד עליכם, ואין כאן איזו התחכמות - איזה רכב הייתם קונים? האם לא ברור שאת Y?
ובכן, בפוסט הזה אראה לכם שיש לא מעט אנשים שהיו ממשיכים לקנות את דגם X. גם אם מדובר בדגם פחות איכותי ויקר יותר.
אני ממש לא יודע מה הסיבה לתופעה הזו. אולי זה הרגל, אולי זו עצלנות, אולי זה חוסר מודעות.
אני בטוח שמאוד קשה להסביר אותה בצורה רציונלית.
באנלוגיה שלנו, דגם X נקרא ״קופת גמל״ ודגם Y נקרא ״קרן פנסיה״.
אם אתם לא יודעים איך עובדת פנסיה, אני ממליץ לקרוא את הפוסט המצוין של אסף, אבל לא זו הפואנטה.
הפואנטה היא כזו - מאז שנת 2008, כספים שמופקדים לקרן פנסיה ולקופת גמל בישראל הם בעלי אותן זכויות בדיוק.
הכספים האלו מושקעים לפי מדיניות ההשקעה של הקרן, וכאשר תבואו לפדות אותם בזמן הפרישה, תקבלו קצבה.
ובגלל שקופת גמל לא יודעת לתת לכם קצבה, תצטרכו בכל מקרה להעביר את הכסף דקה לפני הפרישה לקרן פנסיה כדי שתוכלו למשוך אותו.
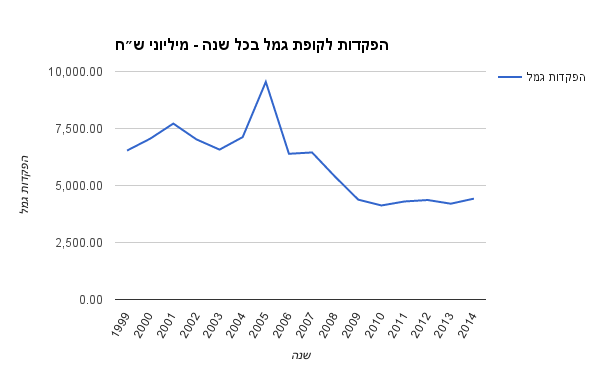
מה מעניין בכל הנושא הזה? ובכן, שני המוצרים כביכול זהים, אבל קרן פנסיה זולה יותר. משמעותית. ואע״פ שקרן פנסיה זולה יותר, אנחנו רואים כספים רבים שמושקעים בקופות גמל כל שנה. כמה זה ״רבים״? בערך 4 מיליארד ש״ח בשנה. שמושקעים במוצר יקר בצורה מהותית.
אז למה בכלל שני המוצרים האלה קיימים אם אין ביניהם הבדלים? ובכן, יש כמה הבדלים היסטוריים, וכמה הבדלים שעדיין קיימים היום.
היסטורית (לפני שנת 2008), קופת גמל אפשרה משיכה של כל הסכום שנצבר בה לאחר 15 שנה, ובצורה של סכום חד פעמי (זה נקרא משיכה הונית), ואילו פנסיה אפשרה רק קבלת קצבה חודשית בגיל הפרישה למשך החיים. לכן, בעבר היה ״יתרון״ כביכול לקופת גמל עבור חלק מהאנשים - אפשר היה למשוך את הכספים בבת אחת, ולא היה צריך לחכות לגיל הפרישה.
בפועל קופת גמל שימשה חשבון חסכון פטור ממס לתקופה של 15 שנה עבור הרבה אנשים.
ההבדל הזה כבר לא קיים היום, כפי שציינתי. בנוסף, עד רפורמת בכר בשנת 2005, הרבה מקופות הגמל הוחזקו ונוהלו ע״י בנקים, ואילו קרנות פנסיה נוהלו ע״י חברות ביטוח. היום גם ההבדל הזה אינו קיים וגם קופות הגמל וגם קרנות הפנסיה מנוהלות ע״י אותם גופים בדיוק (חברות ביטוח ובתי השקעות).
מה ההבדלים שקיימים כיום?
1. קופת גמל היא רק מכשיר לחסכון והשקעה של כסף. קרן פנסיה גם מעניקה לכם גם ביטוח שארים וביטוח נכות - כספים שבני משפחתכם יקבלו אם תעברו מן העולם, וכספים שאתם תקבלו אם תפצעו כתוצאה מעבודתכם. יש מעט קופות גמל שגם מציעות ביטוח חיים יחד עם החסכון, אבל הן מועטות, ובכל מקרה הוא יקר יותר ממה שמציעה קרן פנסיה. הביטוחים האלה עולים עוד כסף, כסף שאתם לא משלמים אם אתם מפקידים לקופת גמל.
2. קרן הפנסיה מכילה ערבות ״הדדית״. הדרך שלה לממן את ביטוח השארים והנכות היא ע״י קיבוץ של מספר רב של חוסכים, והסתמכות על כך שהסיכון יתפזר על כולם. בפועל זה אומר שאם באותה שנה נפטרו או נפצעו הרבה מהחברים בקרן הפנסיה (יותר מהצפוי), הקרן תפסיד כסף ותפגע בתשואה של החוסכים, ואם יקרה המצב ההפוך, הקרן תרוויח כסף, ותשואת החוסכים תעלה. זה נקרא ״תשואה דמוגרפית״.
3. מגוון קופות הגמל גדול יחסית, ויש להן הרבה מסלולי השקעות שונים. ייתכן וחוסכים שמעוניינים במסלולים מסויימים שאינם מוצעים בקרנות הפנסיה יעדיפו את קופות הגמל.
4. דמי הניהול בקרן הפנסיה ובקופות הגמל מוגבלים ע״י החוק, אבל בצורה שונה. קרן פנסיה רשאית לגבות 0.5% מההון הצבור ו - 6% מהכספים המופקדים בכל שנה, ואילו קופת גמל כיום רשאית לגבות 1.05% מההון הצבור ן - 4% מהכספים המופקדים (אלו מספרים החל מ - 2012).
4. לקרנות פנסיה מותר להשקיע באג״ח עם תשואה מובטחת מהמדינה, ולקופות גמל אסור. מהבחינה הזו יש לקרנות הפנסיה יתרון מסוים.
בהנתן ההבדלים האלה, אני מנסה לשאול שלוש שאלות בפוסט הזה:
1. אם קופות הגמל אינן עדיפות והן יקרות יותר, האם משקיעים הפסיקו להפקיד כספים לקופות האלו?
כלומר, האם משקיעים עדיין קונים את המוצר הישן והפחות איכותי שהם רגילים אליו?
2. האם המוצר שנקרא ״קופת גמל״ עדיף על המוצר שנקרא ״קרן פנסיה״ מבחינה איכותית, או להיפך?
בשאלה הזו אני נזהר. קשה מאוד להשוות בין מוצרים שהם שונים ולקבוע מי ״עדיף״. מעבר לכך, הקביעה הזו עלולה להחשב כהמלצה או ייעוץ. אני מדגיש שהיא לא.
3. אם קופת גמל אינה ״עדיפה״, האם היא יותר זולה? כלומר האם דמי הניהול בקופות גמל נמוכים יותר?
נתחיל בשאלה הראשונה: האם עדיין מושקע כסף בקופות גמל
כפי שתיארתי, בשנת 2008 שינו את הכללים עבור קופות גמל, וכל כספים חדשים שהופקדו אליהן מאז אינם ניתנים למשיכה לאחר 15 שנה ובאופן חד פעמי, אלא רק בתור קצבה חודשית לאחר פרישה.
בעקרון זה שינה מאוד את המוצר הזה (שנקרא קופת גמל) והפך אותו לפחות כדאי, כי לפני השינוי תמיד אפשר היה גם למשוך מוקדם ובבת אחת, וגם כמובן להחזיק אותו יותר ולמשוך טיפין טיפין, ולאחר השינוי, אחת האפשרויות התבטלה.
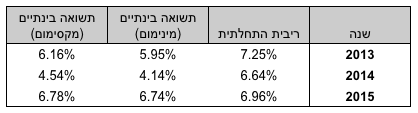
לכן אנחנו מצפים לנפילה בהפקדות סביב שנת 2008, וזה מה שאנו אכן רואים:
מצד שני אנחנו עדיין רואים שמושקעים כספים רבים כל שנה בקופות גמל. בערך 4 מיליארד ש״ח בשנה. לא בדיוק נפילה לאפס.
האם קופת גמל עדיפה על קרן פנסיה?
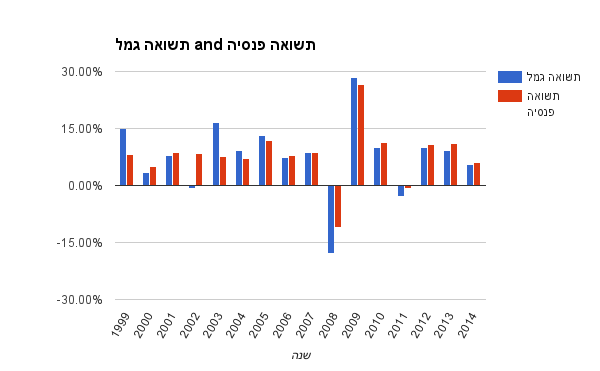
בגרף הבא מושוות התשואות של כלל קופות הגמל לתשואות של כלל קרנות הפנסיה:
העמודות הכחולות מציינות את תשואות קופות הגמל, והעמודות האדומות את קרנות הפנסיה.
כפי שניתן לראות, החל משנת 2005 (רפורמת בכר), התשואות של קרנות הפנסיה וקופות הגמל כמעט זהות, פרט לשנות משבר בהן קרנות הפנסיה השיגו תשואה גבוהה יותר (פחות שלילית), ושנת 2009 בה קופות הגמל השיגו תשואה מעט גבוהה יותר.
בחישוב מצטבר, החל מ - 2008 קרנות הפנסיה עדיפות על קופות הגמל מבחינת התשואה שלהן. זה אמנם לא טווח זמן ארוך במיוחד, אבל היינו מצפים להבדלים חדים יותר אם היה מדובר במוצר שמשקיעים בוחרים בו כי הוא מניב תשואה משמעותית יותר גבוהה.
מעבר לכך, התשואה של קרנות הפנסיה בגרף כוללת גם את התשואה הדמוגרפית. כלומר בינתיים הסיכון של הביטוח ההדדי בין הקרנות אינו פוגע בחברים בקרן.
האם קופות הגמל זולות יותר מקרנות הפנסיה?
בשני הגרפים הקודמים הראיתי שעדיין מושקעים סכומים רבים בקופות גמל, ושקרנות הפנסיה זהות או עדיפות מבחינת התשואה לקופות הגמל.
המסקנה במקרה הזה צריכה להיות שהמוצר הפחות איכותי כנראה זול יותר, ולכן קונים אותו חלק מהלקוחות.
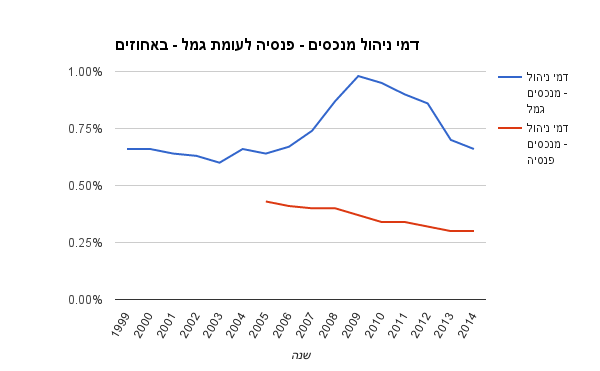
הגרף לסיום מראה את דמי הניהול מהצבירה של קופות הגמל לעומת קרנות הפנסיה:
נתונים על דמי הניהול של קרנות הפנסיה מופיעים באינטרנט רק משנת 2005, אבל כפי שניתן לראות, קופות הגמל יקרות הרבה יותר מקרנות הפנסיה בכספים שהן מנהלות.
איך מסבירים את התופעה?
ייתכנו מספר הסברים ״רציונליים״ לכאורה לתופעה הזו. בואו נראה אם אפשר לפסול אותם:
1. תשואה יותר גבוהה של קופות הגמל - ראינו בגרף שזה לא המצב.
2. לקופת גמל יש יתרון אם אינך מעוניין לשלם על הביטוחים הנלווים - זה נכון, וייתכן שזה מסביר את המשך ההפקדות לקופות הגמל. קשה לי להאמין שזה יסביר 4 מיליארד ש״ח בשנה. האם שווה לשלם פי שניים דמי ניהול בשביל ההזדמנות לא לקנות ביטוח? קשה לי להאמין.
3. ייתכן ודמי הניהול עבור הכספים החדשים שמופקדים יותר נמוכים מדמי הניהול של הפנסיה, ואילו עבור הכספים הישנים (אלה שאפשר למשוך בצורה הונית) דמי הניהול גבוהים בגלל האופציה למשוך אותם כהון.
זה ייתכן, ויותר קשה לפסול את ההסבר הזה בעזרת הנתונים הנוכחיים, אבל חישוב מקורב שעשיתי (הנחתי שדמי הניהול על כסף ישן נשארו כמו ב - 2007, וחישבתי את דמי הניהול על כסף חדש שצריך להתאים לנתונים) מראה שבינתיים קופות הגמל גובות גם יותר דמי ניהול על כסף חדש ולא רק על כסף ישן.
4. לקרנות פנסיה יש דמי ניהול גבוהים מההפקדה, ואילו לקופות הגמל היו רק דמי ניהול מהצבירה. אולי ההבדל מוסבר על-ידי כך?
ובכן - ביצעתי את החישוב עבור הכספים שהופקדו החל מ - 2008 לקופות גמל, והשוויתי לתשואה לאחר ניכוי דמי ניהול מצבירה ומהפקדה אם הכספים היו מושקעים בקרן פנסיה. התוצאות נשארו מאוד דומות.
5. לקופת גמל יש יתרון ארביטראז׳ (תודה לאתגר לוי שעלה על הטריק הזה) - בעקרון אפשר להפקיד כסף לקופת גמל בלי דמי ניהול מההפקדה (יש הרבה כאלה), ודקה לאחר מכן לעביר את הכסף לקרן פנסיה בה דמי הניהול מהצבירה נמוכים יותר. כך חוסכים את דמי הניהול מההפקדה של קרן הפנסיה, כי העברות הן בחינם ולא מוגבלות בכמות או במספר.
זה טריק נחמד (ואפילו כדאי). אם הוא היה מסביר הפקדות של 4 מיליארד ש״ח בשנה, היינו רואים גידול במשיכות מקופות הגמל בהיקף של סכום ההפקדות כל שנה. לא ראינו גידול כזה. להיפך - יש קיטון לאורך זמן בכמות המשיכות.
6. פעם היו כללי מס על כספים מסויימים שיצרו יתרון להפקדה לקופת גמל עבור עצמאים. ייתכן וזה גם המצב כיום, ומה שאנו רואים הוא אותם כספים שמופקדים. את ההסבר הזה קשה לפסול, ואם זה המצב אז זו תוצאה הגיונית לחלוטין. כמות הכספים היא בערך חצי מההפקדות שהיו בעבר, ולכן אני לא בטוח שההסבר הזה סביר לכל הכספים (אבל כאן אשמח לדעת מה דעכם בתגובות אם אתם מכירים את הפרטים).
בקיצור, זו תופעה מאוד מוזרה. ההפרש בעלויות, מחישוב בסיסי שלי הוא בערך 1.6 מיליארד ש״ח ב - 7 שנים. יותר מ - 200 מיליון ש״ח לשנה בדמי ניהול על מוצר שנראה על פניו נחות יותר.
הרבה פעמים שואלים אותי מדוע אין תחרות ויש ריכוזיות בישראל. אני טוען שהבעיה היא לא רק בקיום אלטרנטיבות (״אין מספיק שחקנים״), אלא גם ברצון ובנכונות של הצרכנים לעבור למוצר אחר ממה שהם רגילים אליו, ואשכרה למלא את הטופס שנדרש כדי לקנות מוצר אחר.
הדבר שקול לקניית חלב תנובה בסופר גם אם חלב יוטבתה או טרה זולים יותר, וקשה לכם להבדיל ביניהם אם לא היו עטופים בלוגו אחר.
הוספת תחרות ושכלול השוק מספקת אופציות לצרכנים, אבל הצרכנים בסוף צריכים גם לבצע החלטות בעצמם כדי להרוויח מהשיפור.
הערה לסיום: הפוסט הזה יצא ארוך מהרגיל ועוסק בנושא משעמם ומורכב (פנסיה), אבל הוא מנסה להראות תופעה של התנהגות צרכנים ״מוזרה״ בשוק שיחסית קל למדוד בו את איכות המוצרים ולהשוות ביניהם.
אם יש לכם תאוריות או הסברים אחרים לתופעה, אשמח שתצרפו אותן בתגובה, וכרגיל, אשמח אם תפיצו את הפוסט לחבריכם ותרשמו לרשימת התפוצה מצד ימין למעלה.
ניסוי מפורסם בכלכלה התנהגותית מציג שני אנשים בעלי רקע דומה, יכולות דומות והשכלה זהה:
אדם א׳ מרוויח בשנה הראשונה 100,000 ש״ח, באותה שנה יש 0% אינפלציה, ובשנה השנייה השכר שלו עולה ב - 2%.
גם אדם ב׳ מרוויח בשנה הראשונה 100,000 ש״ח, אבל באותה שנה יש 4% אינפלציה, ולאחר אותה שנה השכר שלו עולה ב - 5%.
את הניסוי מבצעים שלוש פעמים (כל פעם עם קבוצה אחרת) ושואלים אחת מהשאלות הבאות את הנבדקים:
1. מי מרוויח יותר בסוף השנה השנייה במונחים כלכליים?
2. מי מאושר יותר לדעתכם בסוף השנה השנייה?
3. למי לדעתכם יש הסתברות גבוהה יותר לעזוב את עבודתו לאחר השנה השנייה?
מרבית העונים אומרים כי אדם א׳ עשיר יותר בסוף השנה השנייה, אך טוענים במקביל כי אדם ב׳ מאושר יותר, וכי סביר שאדם א׳ יעזוב את העבודה יותר מאדם ב׳.
התופעה הזו מכונה ״אשליית הכסף״ (Money Illusion), וטוענת שאנשים מודדים את העושר הכלכלי שלהם במונחים נומינליים ולא במונחים ריאליים. או במילים אחרות - בכמה כסף יש להם, ולא במה הכסף שלהם יכול לקנות.
תופעה נוספת שמתועדת היטב (ולאחרונה יש לה שימוש ייחודי במחקר) היא ההנחה של אנשים שהעולם הוא דטרמיניסטי, או במילים אחרות, שלכל תוצאה יש סיבה, ומרבית התופעות שאנו רואים הן בשליטתנו.
היקום כמובן אינו מקרי לחלוטין. יש לו חוקיות אבל היא הסתברותית ((כן, אני יודע שהמשפט הזה אינו הגיוני)) - אנחנו יודעים לחזות היטב את הממוצע ואפילו להסביר אותו אבל מאוד קשה לחזות התנהגות של תופעות סביב הממוצע. לפעמים מחירים עולים, ולפעמים יורדים, אבל בממוצע, ולאורך שנים, האינפלציה חיובית כי כך אנחנו מתכננים אותה.
תופעת השאיפה לממוצע (Regression to the mean) אומרת שלאורך זמן תופעה סטטיסטית תחזור לממוצע שמאפיין אותה.
יש לכך הרבה דוגמאות, אבל באופן כללי, אם במשך כמה שנים, לדוגמא, יש בצורת חזקה, ואנחנו לא צופים שינוי מגמה בירידת משקעים לאורך זמן אז אפשר לצפות שלאחריהן יגיעו כמה שנים ברוכות. (להלן שבע השנים הטובות והרעות).
כנ״ל מדובר על מחירי דירות אשר ישאפו לשינוי הממוצע בהן לאורך זמן, אם נניח שהם מגיעים מהתפלגות מקרית סביב אותו ממוצע.
בשבוע שעבר קראתי פוסט מאוד מעניין של הכלכלן אסף צימרינג שהציג נתונים על מחירי דירות בישראל.
בפוסט אסף הציג נתונים מדוח בנק ישראל שמנתחים את עליית מחירי הדירות משנת 2002 עד 2012. הנתונים מראים עלייה עקבית במספר המשכורות שנדרש לקניית דירה החל משנת 2009.
עד עכשיו אני מקווה שלא סיפרתי לכם שום דבר חדש.
תופעה מעניינת שהעלה אסף היא שאולי המחיר ביחס לשכר הממוצע עולה, אבל אם מסתכלים על השכר החציוני של משק בית (ולא בהכרח של אדם בודד), העלייה מתונה הרבה יותר, בעיקר מפני שיותר אנשים במשקי הבית היום עובדים מבעבר.
גם אם השכר הממוצע (או החציוני) לא עלו, אבל משק בית עלה מ - 1.3 מפרנסים ל - 1.5 מפרנסים, אז השכר באותו משק בית עלה בממוצע ב - 15%. במקרה הזה גם עליית מחיר של 15% במחירי הדירות היא סבירה אם כל משקי הבית פתאום עשירים יותר ב - 15%.
השאלה ששאלתי היא מדוע בנק ישראל ביצע מחקר שהסתכל על נתונים החל משנת 2002 בלבד, ומדוע אנו לא יודעים איך השתנו מחירי הדירות בישראל ביחס להכנסת משק הבית במהלך ההיסטוריה.
האם ישראל כרגע בגל עליות יוצא דופן? אולי לא?
החלטתי לבדוק את הנושא, ואני חייב לומר שפרט להנאה של שיטוט באיזורים נידחים של ספריית האוניברסיטה שלי, מצאתי דברים נפלאים בספרים ישנים משנות ה - 50, ה - 60 וה - 70.
פעם היו אנשים מאוד רציניים שאספו נתונים על ישראל. לא ממש ברור לי מה קרה מאז.
הדבר הראשון שעניין אותי הוא איך נראו עליות מחירי הדירות בישראל, כמה רחוק בהיסטוריה שניתן למצוא.
באתר הלמ״ס מצאתי נתונים החל משנת 1963 על עליית מחירי הדירות בכל שנה ביחס לשנה הקודמת. בשנתון הסטטיסטי לישראל של שנת 1974 מצאתי לראשונה פירוט של הנתונים האלה, והם התחילו ב - 1960. מצאתי גם הרבה דברים מעניינים אחרים שאשתדל לכתוב עליהם בעתיד.
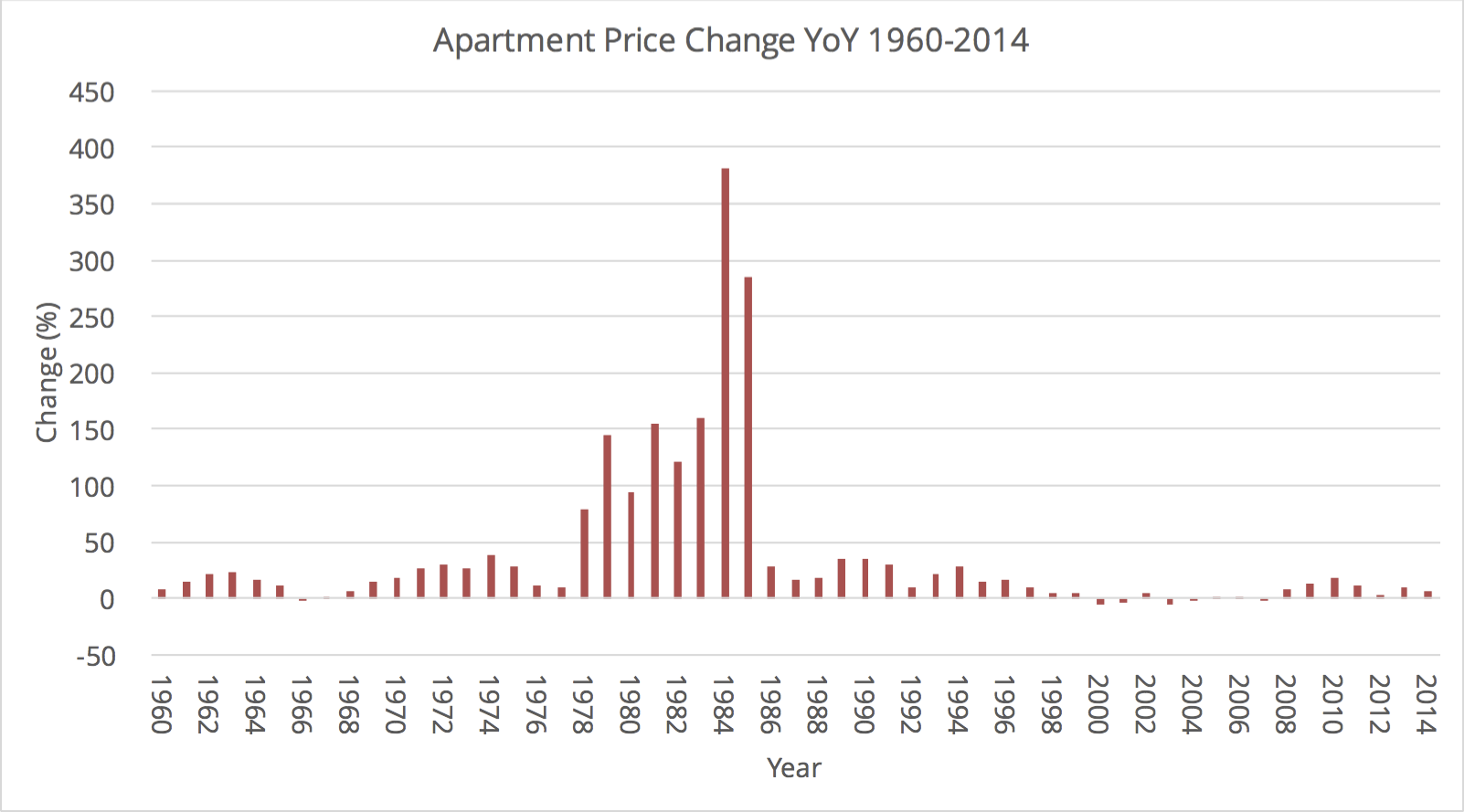
בגרף הבא רואים את השינוי במחיר הדירות, באחוזים לעומת השנה שעברה החל מ - 1960:
שינוי שנתי באחוזים במחירי הדירות 1960-2014. מקור: נתוני למ״ס
שימו לב כמה שמח היה בישראל בשנות השמונים בה מחירי דירות עלו בכל שנה ביותר מ - 100 אחוזים.
עכשיו אני מקווה שאתם חושבים לעצמכם ״איזה ליצן, הוא כרגע הזכיר לנו את אשליית הכסף - זה שינוי במחירים שלא תוקן לאינפלציה״, ואתם אכן צודקים.
לאחר תיקון שינוי המחיר לאינפלציה באותה שנה, מתקבלת התמונה הבאה:
פתאום שנות ה - 80 נראות הרבה יותר שמחות עם זעזועים רציניים במחירי הדירות (עליות וירידות חדות, עד תכנית הייצוב של 1985).
אבל שמים לב לעוד כמה דברים מעניינים:
ישראל חוותה גלים של עליות מחירים ריאליות בהם המחירים עלו במעל 10% בשנה בכל עשור החל מ - 1960. השנים 2009-2014 אינן כה יוצאות דופן.
את הגל של שנות ה - 90 אפשר להסביר בגל העלייה מבריה״מ והמחסור החמור בדירות (למי שזוכר את שכונות הקרוואנים).
אבל איך מסבירים את הגל סביב 1963? או את הגל עד מלחמת יום כיפור ב - 1973?
נניח שניתן למצוא הסברים לכל אותם גלי עליות מחירים (האופוריה אחרי ששת הימים עד 1973, האינפלציה של שנות ה - 80, גל העלייה של שנות ה - 90 וירידת הריבית העולמית של שנות - 10), כיצד ניתן להסביר את שוך הגל? מדוע עליות המחירים נעצרות ומתמתנות ולעתים אף עוברות לירידות מחירים?
ניתן לומר שזוהי חזרה לממוצע, אבל מה גורם לאותה חזרה? ומהו אותו ממוצע? האם זה ממוצע אפס (אין שינוי במחירי הדירות), חיובי (מחירי הדירות תמיד עולים לאורך זמן), או אולי שלילי (מחירי הדירות יורדים לאורך זמן???)
להערכתי יש שלושה גורמים לחזרה לממוצע, ואני מקווה שיימצאו הנתונים לאשש את ההערכות הללו:
למשקי הבית, בשלב כלשהו, יש תקרה לגובה התשלום שהם יכולים לשלם עבור משכנתא. הם יכולים להאריך את המשכנתא בעוד כמה שנים, ואולי לקחת אחוז גבוה יותר של משכנתא לעומת הון עצמי, אבל בסוף, הם חסומים בתשלום של בערך שליש מהשכר שלהם.
המחירים עולים ועולים, אך כשמגיעים לתקרה הזו חלה התמתנות בביקוש.
הממשלה מגיבה - על אף כל הסיסמאות של שרים למיניהם, לדעתי אין לממשלה יכולת להגיב למחסור בהיצע דירות בטווח של פחות מחמש שנים (אולי שלוש במקרה הממש מהיר). תהליכי התכנון והאישור ארוכים, הקבלנים צריכים למצוא עובדים, ובפועל לבנות בניינים לוקח כמה שנים.
הקבלנים מגיבים - כשהמחיר עולה היום, הקבלנים מתחילים לבנות למחר. שנתיים או שלוש לאחר מכן, מתברר שהרבה קבלנים בנו ביחד יותר מדי דירות, ויש היצע גדול מדי, כפי שניתן היה לראות בתחילת שנות האלפיים.
מה שאני מנסה להראות בפוסט הזה הוא שעליות מחיר ריאליות של 10% ויותר בשנה אינן נדירות בישראל. מעבר לכך, חשוב מאוד להתמקד בעליית מחירים ריאלית, ולזכור שתופעות צריך לבחון לאורך תקופה ארוכה כדי לוודא שמדובר בבעיה, ולא פשוט בסטייה רגעית מהממוצע כפי שניתן לראות במקרים רבים.
החיטוט בנתונים הוביל אותי לשאול בכמה עלו באמת מחירי הדירות בישראל על פני השנים, או במילים אחרות האם השקעה בדירות בישראל היא השקעה טובה לאורך זמן. כשאומרים ״השקעה טובה״, צריך להשוות אותה לאלטרנטיבה. במקרה הזה אני מתכנן להשוות לשוק המניות ולשוק האג״ח בישראל.
כשעושים חישוב על הנתונים בגרף, מקבלים עלייה ריאלית ממוצעת של 3.1% במחירי הדירות בישראל מאז 1960. זו עלייה גבוהה מאוד במשך כל-כך הרבה שנים, ואם מוסיפים לה את תשואת השכירות מהשקעה על דירות, נראה כי השקעה בדירות לטווח ארוך הייתה משתלמת בישראל עד היום (אך עדיין הניבה פחות מהשקעה בשוק המניות).
מקור העלייה המתמיד אינו ברור לי. כפי הנראה בחלק מכך מדובר בעלייה באיכות הדירה (בפועל, היא יותר גדולה, ממוזגת, בעלת חניה ושטחים ציבוריים ועוד), אבל את התאוריה הזו צריך לבדוק.
יש סיבה שאני סקפטי לגבי עלייה ריאלית של מחירי דירות לאורך זמן. כדי שהערך של נכס יעלה באופן ריאלי לאורך זמן, צריכים לקרות אחד משני דברים:
ההכנסה/התשואה מהנכס צריכה לעלות. אבל התשואה על ההכנסה (שכירות) בישראל לאורך שנים לא השתנתה ואם בכלל, היא ירדה.
הנכס נהיה יותר נדיר - כלומר הביקוש עולה על ההיצע של דירות. מכיוון שכמות חסרי הדיור בישראל לא עלתה (לא אנשים ללא בעלות על דירות. אנשים ללא דיור), כנראה שיש מספיק היצע של דירות.
התאוריה הכלכלית אומרת שלאורך זמן ארוך (עשרות שנים), מחירי דירות אינם צריכים לעלות בצורה ריאלית כמעט כלל. אם מסתכלים על נתונים של ארה״ב, למשל, זה המצב.
ככל שהמשכתי את הניתוח, הגעתי למסקנה (שמאוד הפתיעה אותי) שמחירי הדירות בישראל, פרט לעיר תל-אביב, לא עלו כלל, ואף ירדו ב - 20 השנים האחרונות.
הכל שאלה של מה מודדים, והיא שאלה שלדעתי מאוד מעניינת.
נשמע לכם לא אמין? בפוסט הבא אנתח את היחס בין מחיר הדירה הממוצע לשכר הממוצע נטו של משק בית (ולא של אדם בודד), כדי לבדוק האם דירות אכן נהיו יקרות יותר בישראל מבעבר, או שאנחנו חווים כאן תופעה אחרת.
אתם מוזמנים להרשם לעדכונים במייל (מצד ימין למעלה), וכמובן אשמח אם תשתפו את הפוסט באמצעי המדיה החברתית השונים.
הפוסט הזה ישב לי בתור כמעט שנה, הוא גם די ארוך, אבל למתמידים מחכה בסוף תמורה - נתונים על התשואה של הלוואות עמיתים בישראל (עד היום).
לפני כשנתיים נפתחה בישראל פלטפורמת e-Loan באתר eloan.co.il להלוואות עמיתים. כשנה לאחר מכן הוקמה Blender, לאחרונה Tarya, ויש גם את B2B שמלווה לעסקים ועוד אתרים נוספים.
למי שלא מכיר את הרעיון, הוא די פשוט - אנשים (לווים) אשר מעוניינים בהלוואה מגישים בקשה באתר כולל מילוי פרטים אישיים ופירוט על ההלוואה. האתר מוודא את הפרטים ומדרג את הסיכון של כל בקשה. המשקיעים (המלווים) יכולים להחליט להלוות להם מכספם בתנאי ריבית שנקבעים על-ידי האתר.
לאורך זמן נוטל ההלוואה משלם את תשלומיו להחזר ההלוואה, ואתם (המלווים) מקבלים את הכסף כולל הריבית לאחר ניכוי עמלות לאורך מחזור ההלוואה.
החברות הראשונות שסיפקו שירות כזה הוקמו באנגליה, אבל הגדולות קיימות בארה״ב משנת 2006 (Prosper) ומשנת 2007 (LendingClub).
בעקבות ההנפקה של לנדינג קלאב בבורסה לאחרונה, רכישת חברת בילגארד הישראלית על-ידי פרוספר השבוע וכמות הפרסומות הבלתי הגיונית של קרן ״קלע״ (כולל החקירה של הרשות לני״ע), נכתבו כתבות רבות על הנושא, ואפילו הבלוג ״תועלת שולית״ ייחד מאמר להלוואות עמיתים.
במאמר מתאר כותב הבלוג (עלום השם?) נתונים ועובדות על מערכת הלוואות העמיתים בעולם, ומסביר היטב מספר נושאים.
בפוסט הזה אני מנסה רק לגעת בשאלת השאלות (האם כדאי להשקיע), ולכן אתייחס רק בקצרה גם לשני הנושאים העיקריים שתיאר כותב ״תועלת שולית״ לקראת הסוף.
לפני שאתחיל, כמה גילויים נאותים הנדרשים במקרים כאלה:
אני מחזיק חשבון שמעניק הלוואות בלנדינג קלאב מתחילת שנת 2012 (שלוש שנים ו - 9 חודשים). התשואה (המתואמת) עליו היא בערך התשואה החציונית עבור אחזקות דומות. זו בדיוק מה שאומרת התאוריה שיקרה לאורך זמן.
אין לי חשבונות בחברות הלוואות עמיתים בישראל. פרט לסיבות של מיסוי ודיווח שעושים את החיים קשים לתושבי חוץ, יש מספר בעיות באתרי ההלוואות העמיתים בישראל שעדיין מונעות ממני מלהשקיע.
אני לא יודע אם חוק ייעוץ ההשקעות הישראלי חל על מי שאינו תושב ישראל, אבל לשם הזהירות, אבהיר שהפוסט הזה אינו ממליץ או מהווה המלצה לשום השקעה או אי ביצוע השקעה.
איך כדאי לחשוב על הלוואות עמיתים
בניגוד לכותבי ״תועלת שולית״, אניח שאינכם יודעים מיהו הארי מרקוביץ׳, ואינכם מריצים חישובי קורלציה על תיקי השקעות ביום יום. אגלה לכם סוד, גם אני לא. יש תוכנות לשם כך, וגם ההנחות במודל של מרקוביץ׳ אינן בהכרח תואמות שינויים בקורלציה בין נכסים לאורך זמן.
אפשר לסכם את התאוריה בכמה פרטים (זה תיאור מאוד מפושט של הנושא, כדי שיהיה על מה לדבר. אם אתם מכירים את הפרטים וקוראים את הפוסט, תשליכו עליו את הידע שלכם).
כשאתם באים לבצע השקעה בנכס חדש, עליכם למצוא נכסים שדומים לו בכמה שיותר פרמטרים, ואז להשוות את התשואה והסיכון בין הנכס החדש והנכסים האחרים. דבר נוסף שכדאי להשוות הוא האם הנכסים מתנהגים בצורה דומה לאורך זמן, או שהתשואות שלהם אינן מתואמות - כלומר כשאחד עולה השני יורד ולהיפך. אם הנכסים כן מתואמים, אין ממש טעם להשקיע בנכס החדש. זה כמו להשקיע יותר בישן.
הנכס שאליו אתם משווים נקרא ״האופציה האלטרנטיבית״, ולאחר שבחרתם אותו, אתם צריכים להחליט אם ההשקעה החדשה טובה יותר מהאלטרנטיבה או לא.
לכן השאלה החשובה היא מה האלטרנטיבה להשוואה להלוואות עמיתים?
״כפי שמתאר ״תועלת שולית״, וגם מתארת ״הסולידית, השקעת כספכם בחשבון הלוואות עמיתים אינה משולה להפקדתו בחשבון פקדון בבנק.
למה בכלל קיים הבלבול הזה? ובכן הוא קיים כי אנשים יודעים שאם הם מפקידים את כספם בבנק, הבנק מלווה אותו לאנשים אחרים בריבית גבוהה, ואנשים זוכרים את הריבית שהם מקבלים על הפקדונות מהבנק שלהם, ולכן מניחים שאת כל ההפרש (מה שנקרא ״מרווח ריבית״), הבנק שומר לעצמו ומנצל אותם.
זה נכון חלקית, אבל לא לגמרי.
הבנק גם מבטיח לכם את הפקדון שלכם בחזרה גם אם מי שהלוו לו את הכסף לא החזיר את ההלוואה.
בנוסף לכך, הבנק גם מאפשר לכם לפדות את הפקדון בכל שלב (הוא מה שנקרא ״נזיל״), ולא אומר לכם ״אני מצטער, הלוויתי את הכסף וההלוואה תחזור רק עוד שנתיים, בבקשה המתן״.
מעבר לכך הבנק גם לעתים מקבל בטחונות על הלוואות מהלווים, ומבצע עוד פעולות רבות כדי להקטין את ההפסד של המפקידים.
לכן, כפי שציינו שני הכותבים בעבר, הלוואות עמיתים דומות לאג״ח לא מדורגות, אשר ידועות גם כאג״ח זבל. זוהי השקעה אלטרנטיבית ששייכת לקבוצת הנכסים הרביעית. במרבית התיקים ההמלצה היא שנכסים אלו לא יעלו על 5% עד 10% מכלל ההשקעות, אלא אם יש לכם סיבה מאוד טובה לכך.
אם אינכם יודעים מהו אג״ח או אג״ח זבל, כנראה שעדיף שלא תשקיעו בהלוואות עמיתים. בקצרה, אגרת חוב (אג״ח) היא הלוואה שניתנת לחברה, והחברה מחזירה את ההלוואה לפי תנאים שונים שנקבעים כשההלוואה ניתנת לה. כדי שאפשר יהיה להעריך את הסיכון בהלוואה ולקבוע לה ריבית, הרבה חברות עוברות תהליך דירוג שקובע להן דירוג אשראי, והוא קובע (בערך) את גובה הריבית שישלמו על ההלוואה. תהליך הדירוג עולה כסף, ובכל מקרה הרבה חברות יודעות שלא יקבלו דירוג גבוה. לכן הן בוחרות להנפיק אג״ח בלי לעבור דירוג, ובתגובה נדרשות לשלם ריבית גבוהה יותר תמורת הסיכון הגבוה יותר לפשיטת רגל או תספורת של החברה. החברות האלו נקראות אג״ח זבל, כי בעבר (ועד היום) ההשקעה בהן מסוכנת ונחשבת ספקולטיבית.
אם אתם נבהלים מהמושג ״זבל״ באג״ח זבל, אין לכם מה להבהל. ניתן להשקיע באג״ח זבל ולהשיג תשואה שכמובן מגיעה עם סיכון גבוה יותר.
מרבית הסטרט-אפים לדוגמא (אם לא כולם) היו מדורגים כחברות ״זבל״ אם היו מנפיקים אג״ח. לכן הן אינן מנפיקות אג״ח ובפועל מרבית האנשים אינם יכולים להשקיע בסטרט-אפים.
מה עושה אתר הלוואות עמיתים
פלטפורמת הלוואות העמיתים מנסות לפתור את פער דירוג האשראי על ידי בניית מודל סטטיסטי שמנסה לחזות את הסיכוי לאי החזרת ההלוואה, ולפי דירוג האשראי הזה קובעות את הריבית שישלם הלווה.
בניית מודל כזה והתאמתו לציבור הלווים לוקחת זמן ומקצועיות, וכאן אנו מגיעים לניתוח של הלוואות עמיתים כנכס להשקעה.
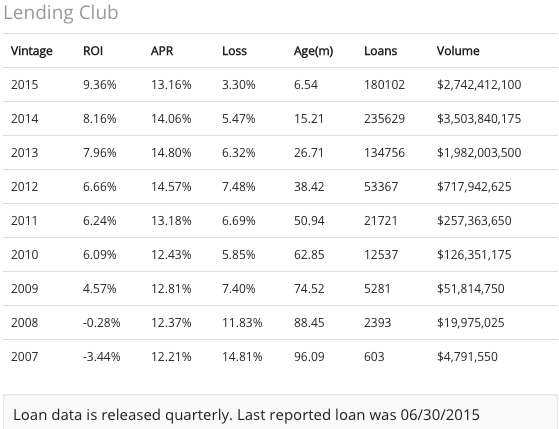
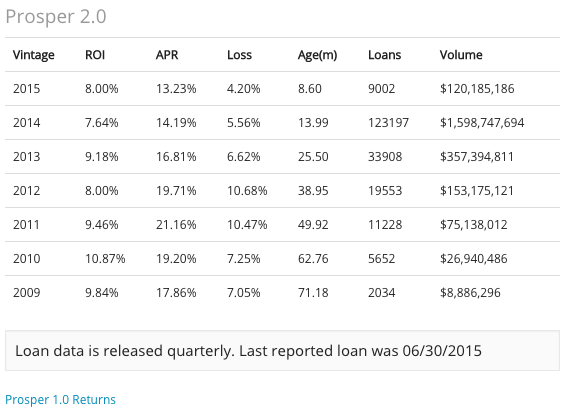
את התשואות של הלוואות העמיתים בארה״ב ניתן לראות כאן:
תשואות לנדינג קלאב. מקור: www.nsrplatform.com
תשואות Prosper, מקור www.nsrplatform.com
הטבלה מציינת לכל שנה את התשואה בפועל (ROI) של כל ההלוואות באתר לאחר ניכוי הפסדים של הלוואות שחדלו פירעון. הלוואות באתר הן בד״כ במשך 36 או 60 חודשים. לכן רק הנתונים עד 2010 כוללים הלוואות שכבר הבשילו ואין להן עוד החזרים בעתיד.
למה זה חשוב? כי הלוואות עמיתים הן נכס מעניין - אנשים לוקחים הלוואה היום, אבל צריכים להחזיר אותה במשך שלוש שנים (36 חודשים). בחודשים הראשונים הם מחזירים את ההלוואה ללא בעיה, אבל לאורך זמן מתחילים להצטבר שוב הקשיים, ולבסוף בחלק מהמקרים הלווה מפסיק להחזיר את ההלוואה.
המשמעות היא שהתשואה יורדת לאורך זמן. כן, בדיוק כמו שאתם קוראים - אם תתחילו להשקיע היום בהלוואות עמיתים ותחכו שלוש שנים, התשואה שלכם תרד לאורך זמן מהתשואה ההתחלתית עד שתתייצב על התשואה הסופית.
אולי גם שמתם לב שאמרתי שפרוספר הוקמה בשנת 2006, אבל הנתונים מופיעים רק משנת 2009. מה קרה לפני כן?
ובכן, לפני כן פרוספר עבדה בשיטה שונה בה אנשים ביקשו הלוואה וכל מלווה החליט באיזו ריבית הוא מוכן לתת כסף, במעין מכירה פומבית יורדת.
התוצאות היו מזעזעות, ומי שהשקיע בשנים הללו הפסיד בממוצע 4.67% כל שנה. כלומר התשואה הייתה שלילית. המשבר הכלכלי של 2008 כמובן לא סייע, אבל המסקנה היא שאנשים אינם טובים בתמחור הלוואות, ולכן עדיף שהפלטפורמה תעשה זאת עבורם.
גם בלנדינג קלאב השנים 2007-2008 לא היו מדהימות, ואתם יכולים לראות את התשואה השלילית בשנים הללו.
התשואה נובעת כפי הנראה משני גורמים (אבל קשה להפריד אותם) - המשבר של שנת 2008, וחוסר הניסיון של הפלטפורמה בתמחור והערכת סיכון.
לקחו לשתי הפלפורמות כשנתיים (וחקירה של הרשות לניירות ערך האמריקאית) לייצב את המודל שלהם כדי להעריך את סיכון האשראי של הלווים.
שימו לב גם לריבית הממוצעת שגובים על הלוואות באתרים הללו (תחת עמודת APR) - הריבית אינה נמוכה מ - 12% ובמקרים רבים נעה בין 14% ל - 20%. שימו לב גם לאחוזי ההפסד (שיעור הכסף המלווה שהלווים לא שילמו חזרה) - מדובר על בין 7% ל - 10% במרבית המקרים.
כלומר - אם תשקיעו את כספכם בהלוואות עמיתים, יש סיכוי סביר (אם נלמד מהמקרה האמריקאי) ש - 10% מהלווים לא יחזירו את כספם. כדי שעדיין תקבלו תשואה רואיה על סיכון כזה גבוה, יש צורך לגבות ריבית גבוהה במיוחד מכל הלווים. כל זה נכון כמובן לשנים שאינן שנות משבר, והאתרים הללו ייבחנו שוב בעת משבר לכשיגיע.
[הערה אנקדוטלית - אולי כלכלנים לא טובים בתחזיות מאקרו, אבל המודלים של תחזיות אשראי לצרכנים שבונים כלכלנים די מדויקים, ולכן הבנק שלכם נותן לכם הלוואה בריבית נמוכה ולשכנכם בריבית גבוהה].
מה קורה בישראל, ולמה הפוסט כזה ארוך?
וכאן אנו מגיעים לאתרים הישראליים - האם כדאי להשקיע בהלוואות עמיתים בישראל?
ובכן, התשובה היא שאיננו יודעים כי האתרים (פרט לאי-לון) אינם מפרסמים נתונים על כמות ההשקעות שביצעו, התשואות וההפסדים שלהן. היכולת שלי להציג נתונים של פרוספר ולנדינג קלאב נובעת מהעובדה שהן מפרסמות באופן חופשי באתר שלהן נתונים על כל בקשות ההלוואות. האתרים האמריקאים הבינו שללא שקיפות מלאה, אין להם סיכוי לשכנע משקיעים להחנות בהם את כספם.
ואילו בישראל? ״תן לי את הכסף ויהיה בסדר״ היא כנראה טכניקה שווקית מוצלחת מספיק.
האתר היחיד (מבין החמישה שבדקתי) שמפרסם את כל הנתונים שלו בצורה חופשית הוא eLoan. הוא גם הותיק ביותר והשקוף ביותר.
הנתונים אינם מפורסמים לצערי בצורת טבלת אקסל נוחה לניתוח כמו האתרים האמריקאים, וגם אינם מפרטים את הניתוחים שדומים לטבלה שהראיתי למעלה.
אבל מכיוון שהם קיימים, אחרי קצת עבודה, ניתן להוציא מהם תובנות:
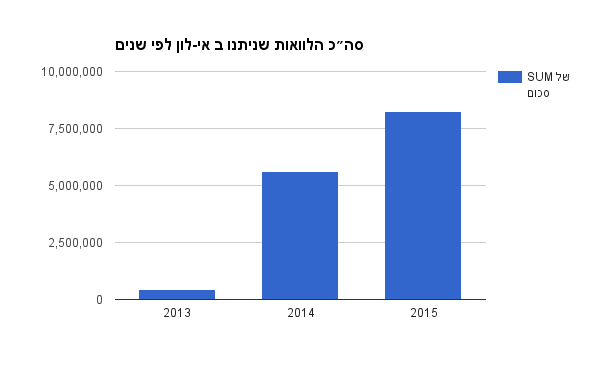
האם כמות ההלוואות שניתנות עם הזמן גדלות?
התשובה בשנתיים האחרונות היא כן, כפי שמראה הגרף הבא:
סכום ההלוואות הכולל בש״ח לפי שנים באתר eloan.co.il. מקור: נתוני אתר אי-לון ועיבוד שלי
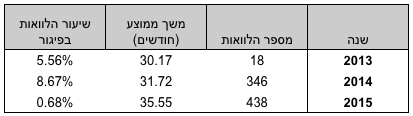
2. האם יש הלוואות בפיגור וכמה באי-לון?
להלן טבלת סיכום של כמות ההלוואות הכוללת שניתנה באי-לון וכמה מתוכן בפיגור באחוזים:
אי-לון התחילה לתת הלוואות באמצע נובמבר 2013, ולכן המספרים עבור שנת 2013 אינם מייצגים.
ההלוואות באתר ניתנות בממוצע לתקופה של בין 30 ל - 36 חודשים (שנתיים וחצי עד שלוש), ומספר ההלוואות גדל עם הזמן, וכפי הנראה גם סכומן ומשך הזמן לו הן ניתנות.
עמודת ״שיעור הלוואות בפיגור״ מציינת כמה הלוואות לא עמדו בתשלומיהן עד היום. הוא לא מציין מהו ההפסד בפועל (שהוא קטן יותר, כי ההלוואות האלו כן שילמו חלק מהחוב עד שנכנסו לפיגור), והוא גם לא מציין מה יהיה שיעור ההפסדים לאורך זמן, כי אנחנו לא יודעים לחזות את העתיד. מהסתכלות בנתונים נראה על פניו כי או שחלק גדול מהפיגור מתחיל להגיע בשנה השנייה לחיי הלוואה, או ששנת 2015 העניקה הלוואות טובות יותר משנת 2014.
3. מה התשואה של משקיעים באי-לון?
לחשב את התשואה כמו שצריך זה חישוב ארוך ומורכב, שאני מקווה שאי-לון מבצעת עבור המשקיעים שלה כמו שלנדינג קלאב עושה עבור לקוחותיה. ביצעתי חישוב מקורב שמעריך את תשואת המקסימום והמינימום נכון להיום.
תשואת המקסימום מניחה שההלוואה נכנסה לפיגור רק ביום האחרון שלה, ותשואת המינימום מניחה שהלוואה נכנסה לפיגור ביום הראשון שלה (ולכן גם לא קיבלתם ריבית על כל הכסף).
מעבר לכך, הנחתי שהמשקיע משקיע בכל ההלוואות באתר סכום זהה (נניח 100 ש״ח בכל הלוואה), ולא בהכרח בוחר הלוואות ספציפיות או משנה את הסכומים.
למה הנחתי את זה? כי התאוריה אומרת שלא תהיה לנו שום דרך להביס את השוק לאורך זמן, אז עדיף שכבר נקנה את כל הנכסים בשוק לשם פיזור הסיכון.
והרי התוצאות:
הריבית ההתחלתית היא הריבית הממוצעת שגובה אי-לון על כל ההלוואות באותה שנה.
ה״תשואה בינתיים״ היא התשואה בפועל לאחר ההפסדים שהיו, תוך הנחה שמי שלא פיגר בהלוואה עד היום לא יפגר בעתיד. כפי שציינתי תשואה זו צפויה לרדת לאורך זמן בגלל שעוד הלוואות ייכנסו לפיגור.
סיכום
הרי לפניכם נתוני אי-לון (ככל שיכולתי למצוא אותם) לאחר 22 חודשי פעילות.
האם זו השקעה כדאית? תלוי באלטרנטיבות שלכם, ובטעם שלכם לסיכון.
האם זו השקעה מסוכנת? בהחלט. אבל גם השקעות בנדל״ן, זהב, וסטרט-אפים הן מסוכנות, ואם אתם לא מבצעים כאלו, קרן הפנסיה שלכם מבצעת כאלו בשמכם.
האם הסיכון מתאים לתשואה? איננו יודעים באמת, אבל אם התשואה תרד עם הזמן לרמה של 3%, כנראה שהסיכון אינו תואם לתשואה.
כפי הנראה לווים בישראל מחזירים את ההלוואות בצורה סדורה יותר מלווים בארה״ב, אבל שימו לב לפערים בריבית ההתחלתית - בארה״ב כדי לפצות על הסיכון הריבית ההתחלתית גבוהה פי שתיים מבישראל. הסיבה היא בעיקר מגבלות החוק בישראל על גובה הריבית שמותר לגבות על הלוואות, וכמובן האלטרנטיבות בשוק שמציעות הלוואות זולות מחברות האשראי.
ולסיכום, כמה נושאים:
למה איני משקיע בהלוואות עמיתים בישראל?
יש לכך כמה סיבות:
דיווח המס בארה״ב על חשבונות זרים מעיק, עולה לא מעט כסף וזמן, ולא שווה את זה, אבל זו לא באמת בעיה אם היה רצון אמיתי.
כפי שהראיתי, האתרים אינם מאוד שקופים כלפי המשקיעים.
הבעיה העיקרית שלי כיום היא שהאתרים אינם מאוד שקופים כלפי הלווים, ובהלוואות עמיתים, יש גם מטרה חברתית של סיוע לאחרים שזקוקים להלוואה. על ההלוואות באתרים הללו נוספות עמלות לא מעטות (ככל שמצאתי אותן) שבפועל מעלות את הריבית המשולמת על ההלוואה בכ - 2% ואף יותר אם חישבתי נכון. החוק בישראל אינו מגדיר היטב כמו בארה״ב את ההבדל בין ריבית לעמלה, ולכן דוחפים ללווים ריבית בתור עמלה. זה לא הוגן כלפי הלווים.
אם תסתכלו על הסיבה ללקיחת הלוואה בארה״ב, תראו שעיקר הסיבות המצוינות הן מיחזור הלוואות והקטנת חוב האשראי. כלומר ״יש לי חוב בריבית יותר גבוהה, ואני רוצה להקטין את הריבית שאני משלם״. זו החלטה כלכלית חכמה, ואני שמח לתמוך בה. מרבית הסיבות לבקשת הלוואה באתרים הישראליים (ככל שראיתי) הן לצריכה - רכישת רכב, מימון נופש ועוד כהנה וכהנה. כאן אתם לא מחליפים את הבנק, אתם פשוט עוזרים למישהו להכנס ליותר חובות.
ובנוגע לביקורת שהעלה ״תועלת שולית״ על הלוואות עמיתים, הנה ניתוח קצרצר:
המקורות - ״תועלת שולית״ מציין שמרבית המלווים באתרים האמריקאיים הם אותם בנקים שהלוואות עמיתים מנסות להחליף, ולכן זהו מוצר משלים ולא תחליפי. ואני שואל ״אז מה?״. האם ניתנת לכם היום הזכות להצטרף לבנק להשקיע במה שהוא חושב שהיא השקעה טובה, באותם תנאים ולקבל תשואה חזרה? האם הבנק שלכם פנה אליכם לאחרונה ושאל אם תרצו להצטרף אליו להשקעה בסטרט-אפ או בנדל״ן? לדעתי לא. העובדה שהמוסדיים נוהרים להשקעות עמיתים יכולה להעיד שדווקא אלו השקעות טובות מאוד. אני זהיר ואומר ״יכולה״ כי כבר ראינו מה קרה כשהמוסדיים השקיעו בנדל״ן סאבפריים, אבל אז לציבור לא ניתנה יכולת להשתתף בחגיגה. באופן כללי, להשקיע בנכס מסוים כדי ״לדפוק את הבנק״ זו לא אסטרטגיית השקעה טובה. עדיף להשקיע בנכס מסויים רק אם הוא יותר טוב מהבנק.
נוטלי האשראי - ״תועלת שולית״ מציין שהמלווים ששים יותר להלוות מאשר הלווים ללוות. הבעיה האפשרית במקרה הזה היא שההלוואות ניתנות בריבית נמוכה מדי לעומת הסיכון שלהן. מעבר לכך, איני מבין את הביקורת.
השימוש באשראי - ״תועלת שולית״ מציין שהלוואות עמיתים הן מוגבלות כי אינן יכולות לכסות גם משכנתאות וקווי אשראי ולכן יישארו תחום נישתי. ייתכן וכך יהיה, אך כבר כיום ישנן חברות שמאפשרות מתן משכנתאות (ע״ע SoFi), אבל בגלל מורכבות ההשקעה הן פתוחות רק למשקיעים מתוחכמים בשלב זה, אבל כך גם ההלוואות החברתיות בארה״ב.
זהו נכס מסוכן ואין לנו מספיק מידע עליו - נכון מאוד. כל השקעה אלטרנטיבית היא מסוכנת.
האם רמי לוי שולח אותך לקנות בשופרסל? לא, אבל בנק השקעות בהחלט יציע לך נכסים של בנק השקעות אחר, ושל חברות מתחרות. הכל תלוי בנכס, במשקיע ובהסכמים שקיימים שם. אני עדיין לא ממליץ ללכת לקנות גשרים אקראיים.
אני חושב שטוב שהתחום מתפתח בישראל, ויהווה או תחרות לבנקים, או גורם משלים לבנקים, אבל בכל מקרה יהווה נכס השקעה נוסף למי שמעוניין. בעיות הנזילות ותמחור הסיכון ייפתרו כאשר האתרים יכווננו היטב את האלגוריתמים שלהם.
האם כל העיסוק בנושא שווה את המאמץ עבור תחום שיהווה אולי 5% מתיק הנכסים של הציבור במקרה הטוב?
לדעתי כן.
מה שכן, ללא שקיפות מלאה של נתוני ההלוואות והתשואות ושינוי התרבות על האתרים השונים, המצב יישאר נישתי או מסוכן כפי שהוא כיום.
״אני לא מבין איך מישהו במדינה הזו סוגר את החודש״. ״המצב בקנטים״.
זה משפט שחוזר על עצמו לעייפה בכל מיני מפגשים, שיחות ודיונים שאני שותף להם.
בחודש האחרון אפילו התפרסמו כמה מאמרים, דוחות ונתונים שמנסים לתאר את המצב הכלכלי בישראל.
מהמושקעים שבהם היא הרשומה בבלוג המצוין של של אורי כץ, אשר מנסה לפשר על הפער הבלתי מוסבר בין הסנטימנט השלילי של מדד אמון הצרכנים בישראל (מהגרועים במדינות המפותחות), לבין הנתונים על שיפור מתמיד בכלכלת ישראל, משנות ה - 70, משנות ה - 2000 ובערך מכל נקודת זמן שתבחרו.
ההסבר של אורי ואחרים הוא שהציבור קונה את מה שמוכרת לו התקשורת, והתקשורת היא גם שטחית, וגם בהכרח מציגה חדשות שליליות (כי חדשות חיוביות לא מוכרות עיתונים, או באנרים). יש שם גם איזו תאוריה על האשמת הממשלה במצב ועוד כמה הסברים.
את ההסבר הזה אורי מגבה בהרבה מאוד נתונים, וקשה להתכחש אליהם. האוסף המרשים של הנתונים מראה שהמצב בישראל משתפר כמעט בכל מדד אפשרי לאורך תקופה ארוכה, ובטוח שאינו במגמת הדרדרות. שני חברים שאלו אותי מה דעתי על הנתונים והרשומה. אז דנית ואופיר, הפוסט הזה הוא בשבילכם.
אורי מסביר היטב את ההבדל בין המגמה בישראל, לבין המצב יחסי למדינות אחרות - אולי המצב אינו טוב אבסולוטית או יחסית למדינות אחרות, אבל הוא בהחלט משתפר עם השנים. וכמו שאמרתי, לא ניתן להתכחש לנתונים - המצב בישראל משתפר.
כלכלנים בד״כ מניחים שהציבור אינו מטומטם, ולא רק שמניחים שאינו מטומטם, אלא שלאורך זמן, מניחים שלציבור יש ציפיות רציונליות שמתממשות. במילים אחרות - בהנתן מספיק זמן, תחושות הציבור בסוף יתממשו, או שהציבור יתקן את תחושותיו ויתאים אותן למציאות.
איך מפשרים בין הנתונים המרהיבים של ישראל על השיפור המתמיד עם תחושת הנאחס שתקפה לאחרונה את הציבור?
ההסבר הפשוט (שמציג אורי) הוא שישראלים מבלבלים בין מצב יחסי לבין מגמה. אם ישראל צומחת ב - 2% בשנה, ושאר העולם ב - 3% בשנה, אז אולי המצב בישראל משתפר תמיד, אבל אם תעלו לברלין, אולי שם ישתפר מהר יותר.
אני אציג הסבר חליפי, ואנסה לגבות אותו בנתונים ככל האפשר. אני לא חושב שהישראלי הממוצע (והפסימי) פותח את מחירון המילקי בברלין כל בוקר ובודק האם המצב שם טוב יותר כדי להחליט על מצב הרוח שלו היום.
אני חושב שהישראלי הממוצע פשוט פותח את חשבון הבנק שלו, ומחליט על פי מצב החשבון האם הוא פסימי או אופטימי.
1. העם דווקא אופטימי
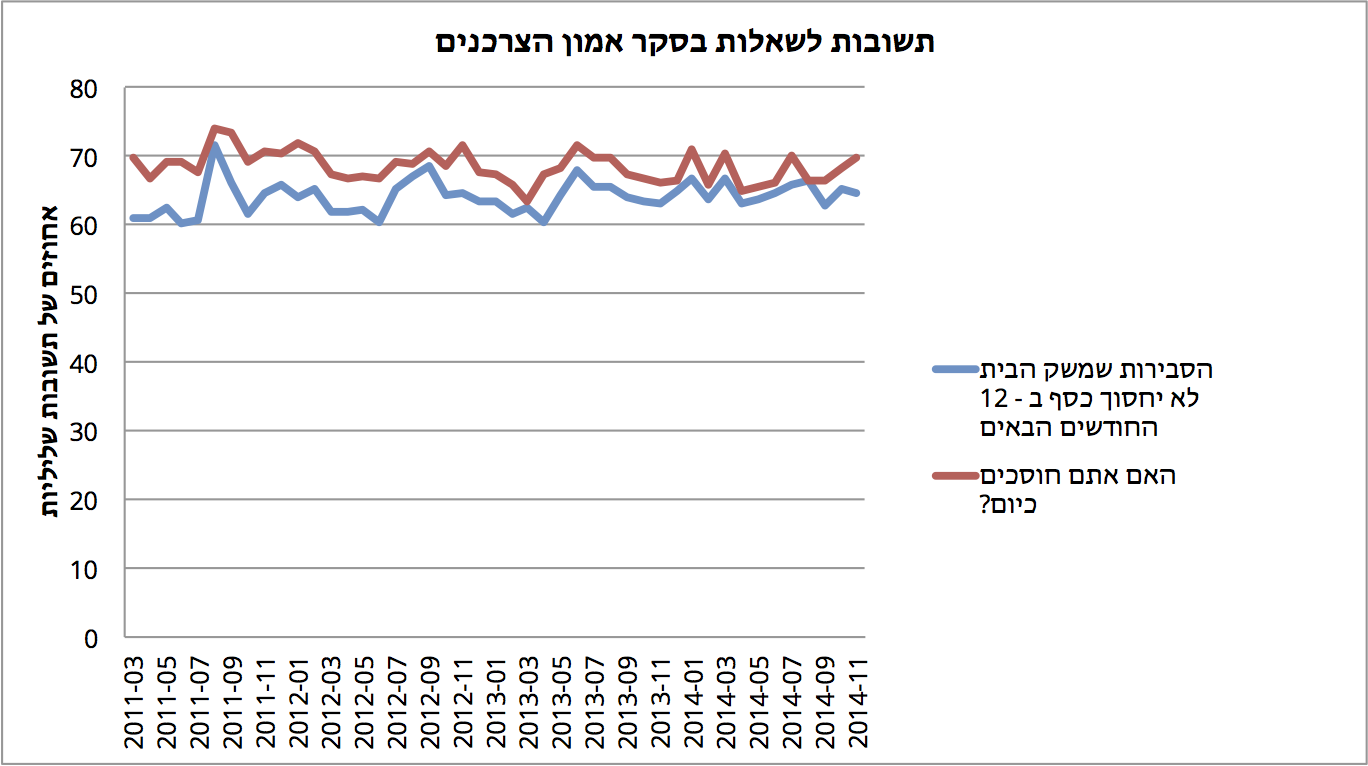
נתחיל במדד אמון הצרכנים שאורי ציטט. המדד הוא שיקלול של תשובות למספר שאלות ששואל הלמ״ס מדגם של תושבים בישראל כל חודש. את הנתונים ניתן למצוא באתר הלמ״ס. ((http://www1.cbs.gov.il/ts/databank/building_func.html?level_1=28))
שתי שאלות מאוד מעניינות קיימות בסקר: ״מהי הסבירות שמשק הבית יחסוך כסף ב - 12 החודשים הבאים״, וגם ״מהו המצב הכלכלי הנוכחי של משק הבית״.
הגרף הבא מתאר כמה אחוזים מהקהל שענה לסקר ענו תשובות שליליות: ״לא כל כך סביר״ ו״בכלל לא סביר״ על הסיכוי לחסוך כסף ב - 12 החודשים הבאים, ו״ההכנסות מספיקות רק כדי לכסות על ההוצאות״, ״אנחנו נאלצים להשתמש בחסכונות כדי לכסות את ההוצאות״ ו ״אנחנו בחובות״ לשאלת המצב הכלכלי הנוכחי.
מקור: נתונים: למ״ס, עיבוד: עצמי
ככל שהתוצאה גבוהה יותר בגרף, המצב רע יותר. ניתן לראות שמעל לשלוש שנים (מאז 2011), בין 65% ל - 75% מהאוכלוסיה אינה מצליחה לחסוך כסף כלל. בנוסף, בין 60% ל - 70% אינם מאמינים שיצליחו לחסוך ב - 12 החודשים הבאים.
הנתון הזה יכול להסביר את אמון הצרכנים - מי שבסוף החודש הוציא יותר משהכניס, אינו מרגיש טוב עם המצב. זו אינה השוואה לחו״ל. זה פשוט תיאור מצב.
הדבר המעניין הוא שהעם דווקא די אופטימי - הקו הכחול תמיד נמוך מהקו האדום - גם אם הרבה אינם חוסכים כיום, חלק מהם מאמינים שיחסכו בתקופה הקרובה.
2. העם חוסך הרבה, אבל נכנס למינוס.
שתי שאלות ממדד אמון הצרכנים הראו שבאופן עקבי מרבית הישראלים אינם מצליחים לחסוך כספים כל חודש. מצד שני באים נתוני הלמ״ס ומראים שפרט לשלושת העשירונים התחתונים, 70% ממשקי הבית כן חוסכים כספים.
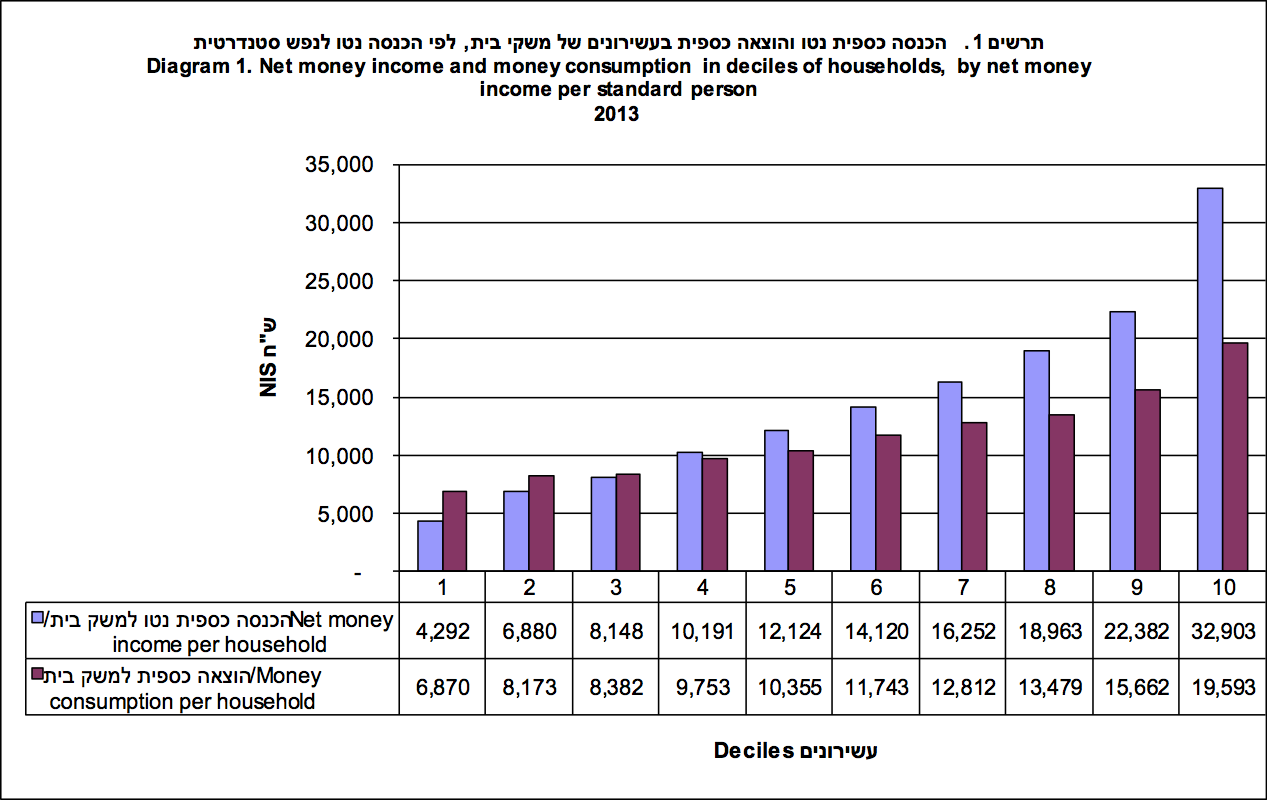
לדוגמא, זה הגרף שפורסם ע״י הלמ״ס שמסכם תוצאות ראשוניות של נתוני שנת 2013 על הכנסות והוצאות נטו של משקי בית לפי עשירונים:
מקור: למ״ס
בתרשים ניתן לראות בצבע כחול את ההכנסה הכספית נטו של משק בית בכל עשירון בישראל, ובסגול את ההוצאה הכספית נטו.
לא אכנס כאן להסבר של איך מחלקים את האוכלוסיה לעשירונים ((לפי ההכנסה נטו לנפש סטנדרטית)) , אבל בעקרון ניתן לראות שעשירונים אחת עד שלוש מוציאים יותר ממה שמכניסים, ואילו עשירונים 4 עד 10, מצליחים לחסוך חלק נכבד מהכנסתם, וגומרים את החודש יפה.
בקיצור - משק בית שמכניס מעל 10,000 ש״ח נטו לחודש לערך, לא אמור להיות בחובות לאורך זמן.
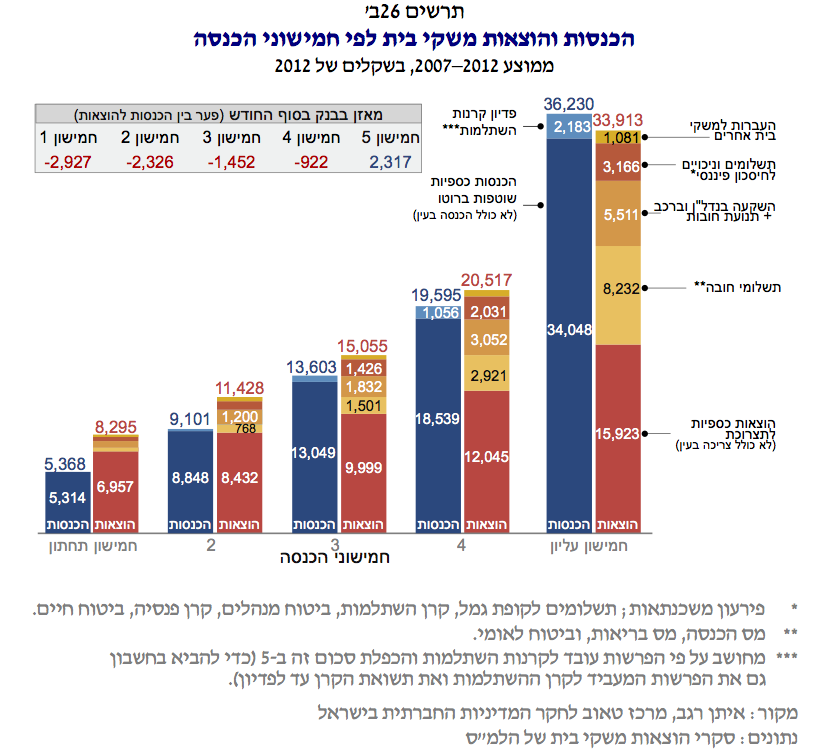
כחודש לאחר מכן פרסם מרכז טאוב את דוח מצב המדינה השנתי שלו. בדוח יש פרק שכתב איתן רגב ומנתח את הנתונים של אותו הסקר שערך הלמס. הוא מנתח נתונים בעיקר של שנת 2011 כי לא היו בידיו את נתוני 2013 בזמן כתיבת הדוח.
איתן פרסם גרף דומה לזה של הלמס, אבל הוא מחולק לחמישונים. החמישון הראשון הוא כמו העשירון ה - 1 וה - 2, החמישון השני הוא כמו העשירון ה - 3 וה - 4 וכן הלאה.
מכיוון שמדובר באותם נתונים (אמנם של לפני שנתיים), לא אמור להיות שינוי מגמה דרמטי. אנו מצפים שהחמישון הראשון (וכנראה השני) לא יגמרו את החודש, ואילו השאר ייוותרו עם סכום נאה בבנק בסוף כל חודש.
רק לשם השוואה, לקחתי את נתוני הלמ״ס משנת 2011, חילקתי אותם לחמישונים, וייצרתי גרף דומה לזה שלמעלה:
מקור: נתונים: למ״ס. חיבור וחיסור: עצמי. שכחתי את סימון הצירים. מנחה מעבדה ב׳ שלי מתהפך בשנתו.
העמודה הסגולה מציגה את ההפרש בין ההכנסות להוצאות. כצפוי, החמישון הראשון והשני (בין 30% ל - 40% מהאוכלוסיה) אינו סוגר את החודש, ואילו השאר במצב טוב.
הגרף של מרכז טאוב מעניין במיוחד כי מעבר להוצאה הכספית על צריכה, הוא כולל את כל ההוצאות של משק הבית.
הרי הגרף:
תשלומי החובה הם מס הכנסה, ביטוח לאומי ומס בריאות. תשלומים וניכויים לחסכון פיננסי הם הפרשות לפרישה (פנסיה) וקרן השתלמות. העברות למשקי בית אחרים הן מתנות. לא רק מתנות לחתונה - גם כשעוזרים בקניית דירה או בתשלום לחתונה זו מתנה.
לבסוף, החזר חובות, תשלום על משכנתא ורכישת רכב (בתשלומים, הלוואה) גם מופיעים בכל עמודה.
הלמ״ס סופר בד״כ רק את ההוצאה הכספית לתצרוכת, ואת תשלומי החובה בתור הוצאות של משק הבית כל השאר מוגדר כחסכון.
כאן טמון הפער, או ההבדל בין מה שהלמס מגדיר נטו, או מה שרוב מי שאני מדבר איתו מגדיר נטו - הכסף שמגיע בסוף לחשבון הבנק. כתבתי על חלק מהפער לפני כמה שנים.
שימו לב כי כעת, במקום שני החמישונים התחתונים שנמצאים בחובות, לפחות 80% מהאוכלוסיה לא סוגרת את החודש, וגם המצב של ה - 20% העליונים אינו מזהיר.
למה זה חשוב? כי החל מלפני כמה שנים יש בישראל חוק פנסיה חובה. לעובד אין אופציה לקחת את הכסף ולשלם חובות - הוא חייב לשים אותו בצד לחסכון עתידי. זו החלטה כלכלית נבונה לחסוך לעתיד בריבית של 8%, אבל לא אם אתה נאלץ לשלם ריבית של 10% על חוב כרגע לשם החסכון הזה...
מעבר לכך, להתייחס להשקעה בדירה כחסכון זה מצוין, אבל היכולת להתמודד עם ההוצאה הזו בטווח הקצר (12 החודשים הקרובים) היא כמעט ולא קיימת. נניח שאתם גרים בדירה שקניתם ואתם משלמים עליה משכנתא. נניח ונקלעתם לחובות ותרצו לעבור לדירה זולה יותר. תוך כמה זמן תוכלו לאתר דירה אחרת, למכור את שלכם, ולעבור לחדשה? במיוחד אם יש לכם ילדים, מדובר בשנת לימודים, יש בני זוג וכו׳ וכו׳?
בקיצור - אמנם ההוצאה הזו של משקי הבית היא הוצאת חסכון, אבל היא אינה גמישה כל-כך בטווח הקצר.
החסכון של רוב משקי הבית בישראל הוא ״מוזר״ קצת, כי הוא ברובו עקיף. זה לא שבסוף החודש משק הבית לוקח את הכסף שנשאר ושם אותו בתכנית חסכון. המעסיק לוקח ממשק הבית כסף בתלוש השכר ושם אותו בפנסיה/קופת גמל/ביטוח מנהלים, והבנק לוקח את תשלומי המשכנתא ושם אותם, ובכן, בחשבונו. זו תוצאה של רגולציה ישראלית ואהבה ישראלית לרכישת דירות.
לצערי, רכישת דירות הוא המדד היחיד שבו אורי כץ הראה שהמצב בישראל אינו במגמת שיפור לאחרונה.
גם תכנית החסכון האהובה על ישראלים (הדירה, הדירה) נלקחת לאט לאט הרחק מהישג ידם. אולי זה חיובי, כי הכסף שיתפנה ילך לחסכון ישיר, וכולם יהיו אופטימיים.
לפני חצי שנה בערך התפרסם ספרו של תומאס פיקטי "קפיטל במאה ה - 21", ועשה הרבה רעש. תומאס פיקטי הוא כלכלן צרפתי שאסף במשך שנים נתונים על הכנסה ועושר שנמסרים לממשלות במסגרת דיווחי מס. הוא ניסה לחשב כמה עושר מרוכז אצל המאיון העליון, האלפיון העליון וכו'.
לא קראתי את הספר (כמו 98% ממי שקנו את רב המכר, כפי הנראה), אבל תמציתו היא שבשנים האחרונות יש ריכוז עצום של עושר בידי שכבה דקה של עשירים וגידול באי השויון הכלכלי בעולם.
עמנואל סאאז וגבריאל זוקמן, שני כלכלנים מברקלי פרסמו לאחר צאת הספר נתונים מעודכנים שמראים את הגרף המדהים הבא:
הגרף מראה את החלק מכלל העושר (כלומר מכל הנכסים) שנמצא בידי האחוזון העליון בארה"ב. הקו המעניין הוא הקו האדום. הקו הזה מראה את העושר שנמצא בידי ה - 0.01% העליונים, או בעברית, המאיון העליון של המאיון העליון בארה"ב. ב - 2012 אותם 16,000 אנשים החזיקו במעל 10% מכל העושר בארה"ב. הכל כולל הכל - נדל"ן, מניות, כסף מזומן, זהב, מכוניות. מה שתרצו.
אתם בטח חושבים לעצמכם - טוב, זו ארה"ב, מדינה עם מיסים נמוכים, קפיטליזם דוהר, ובאופן כללי, לא מנסים לצמצם בארה"ב את אי השוויון.
אני אתכם. אותי עניינו הנתונים על ישראל, אבל אם תקראו בעיון את הראיון בדה-מרקר עם פיקטי, תראו שהוא מציין שהוא פנה לרשויות בישראל מספר פעמים לקבל נתונים על עושר האוכלוסיה, אך הן סירבו למסור אותו או טענו שאין אותו בידיהם.
יש משהו בטענה הזו. מס הכנסה בישראל מקבל בעיקר נתונים על הכנסה, לא על נכסים. מכיוון שבישראל אין מס ירושה ומס מתנות, גם אין ממש חובה לדווח על נכסים חוץ מבמקרים מסוימים, ובאופן כללי קשה לאסוף את הנתונים.
לשם סיבור האוזן, אם מסתכלים על התפלגות ההכנסות בישראל ולא על התפלגות הנכסים (כלומר משכורות, דיבידנדים ורווחי הון, וכו', ולא שווי נדל"ן לדוגמא), אזי המאיון העליון הכניס בשנים 2011 רק 12.7% מכלל ההכנסה בישראל. ((מקור: דוח מנהל הכנסות המדינה ))
אני אומר "רק", כי בכל זאת, מדובר בכל המאיון העליון, שהם בערך 33,000 איש, ובנוסף להרבה ישראלים יש נכסים בדמות הדירה בה הם גרים, חסכון לפנסיה וכו'. כלומר, נראה על פניו שפי שניים אנשים מבארה"ב (ופי מאה מחלקם באוכלוסיה) מחזיקים בערך באותו חלק של הנכסים באוכלוסיה. כל זה תלוי בהנחה שהתפלגות ההכנסות מייצגת את התפלגות הנכסים. משמע - ישראל הרבה יותר שוויונית. העשירים מאוד עשירים, אבל יש הרבה כאלה ולא מתי מעט.
למזלנו, ישראל מדינה קטנה. קטנה מאוד. יש בה רק כ - 8.2 מיליון תושבים, מתוכם כ - 3.3 מיליון משלמי מס. אז 0.01% מהאוכלוסיה הם בערך בין 350 ל - 850 איש.
בכל שנה אתר דה-מרקר מפרסם את רשימת "500 עשירי ישראל". הרשימה כוללת אנשים בודדים ומשפחות, אבל ניתן בקלות להעריך שהם מהווים בין 0.01% ל - 0.02% מהאוכלוסיה הרלוונטית.
אנחנו מדברים על כמה מאות אנשים סה"כ. לא על עשרות אלפים. את סה"כ הנכסים שלהם לאורך השנים תיעד דה-מרקר בגרף הבא:
מקור: http://www.themarker.com/magazine/1.2338208
בשנת 2012 למשל, היו בידי 500 העשירים של ישראל 84 מיליארד דולר של נכסים.
אני לא יודע כמה דה-מרקר מדויק, אבל אלו הנתונים הכי טובים שמצאתי. מצד שני, הם יכולים לתת לנו הערכה טובה יחסית לתשובה לשאלה - כמה אחוז מכלל הנכסים בישראל שייכים סה"כ ל - 500 משפחות המהווים כ - 0.01% מהאוכלוסיה.
אני אתן לכם לנחש - האם 1%? אולי 5%?
התשובה די מפתיעה.
כדי למצוא אותה צריך לדעת מה השווי הנקי של הנכסים שיש בידי כלל משקי הבית בישראל. כמו שאמרנו, אין לנו נתונים ממס הכנסה, אבל יש לנו נתונים מהמאזן הלאומי המאוחד שמפרסם הלמ"ס כל שנה. המאזן הזה מפרט את כל הנכסים וההתחייבויות של הסקטורים השונים במשק (הציבור, חברות, ממשלה וכו').
אספתי את הנתונים האלה ((מקורות: למס 1, למס 2, למס 3, למס 4)), והכנתי את הגרף הבא:
התוצאות די הפתיעו אותי. בשנת 2012, עבורה יש לנו את המספרים הכי עדכניים, כ - 12% מכלל העושר בישראל הוחזק סה"כ ע"י 500 אנשים.
כפי הנראה, האחוז הזה עלה מאוד בשנתיים האחרונות, אבל צריך לחכות לנתונים של המאזן הלאומי כדי לוודא.
אין לי איזו מסקנה מיוחדת לפוסט הזה לאור הנתונים, פרט לעובדה שייתכן וישראל דומה יותר לעולם מכפי שחושבים.
ראית שהסולידית כתבה עליך?". כך נפתחו שלוש הודעות שקיבלתי שבוע שעבר בעקבות הפוסט "למה קשה כל-כך לפרוש מוקדם בישראל". ההתייחסות של דורין היא לפוסט שכתבתי לפני כחצי שנה עם הכותרת "לא סולידית?" ובו טענתי שקשה מאוד ליישם את שיטות החסכון המומלצות על-ידי הבלוג במשכורת ישראלית ממוצעת, ולכן השיטה אינה רלוונטית לכ - 75% מהאוכלוסיה.
בפוסט החדש שלה, קובעת הסולידית שהשיטה שבה היא תומכת היא אוניברסלית ומוכחת מתמטית, ומי שמבקר וטוען שאינה ישימה בישראל "נתפס לקטנות" ומפספס את התמונה הגדולה.
הסיבה העיקרית, לטענתה של דורין, לקושי לפרישה בישראל היא תרבות ההחצנה הישראלית. התרבות שמקדשת צריכה מוחצנת והתנהגות מוחצנת. לו רק היינו מופנמים יותר או מרגישים בנוח להפנים את צריכתנו, לא היה לישראלים קושי כלל להגיע לפרישה מוקדמת.
החלטתי להשקיע קצת מחשבה בנושא, אם זוהי אמת "אוניברסלית", איך ייתכן שהמספרים אינם מסתדרים? בסוף מצאתי פתרון, לדעתי חדשני, אך קל מאוד לביצוע. אני אציג אותו בהמשך הפוסט בשיטה שאני מכנה UERE - Ultra Early Retirement Extreme. היתרונות בשיטה הזו היא שכל אחד מכם כבר רגיל אליה ומנוסה בה היטב והיא יעילה הרבה יותר משיטת ERE שעל עקרונותיה ממליצה הסולידית.
לפני הצגת פרטי השיטה, כמה מילים חיוביות. אני חושב ש"הסולידית" הוא בלוג מצוין לחינוך פיננסי בתחום ההשקעות ("מה לעשות אם יש לי כסף פנוי"), ואיני מופתע שהוא הפך לאחד הבלוגים הנקראים בישראל בתקופה כה קצרה. דורין היא כותבת מוכשרת אשר משכילה לקחת עקרונות השקעה אוניברסליים אשר מגובים בניסיון, היסטוריה ומחקר רב, ולתרגמם ולהציגם היטב לקורא הישראלי, תוך ההתאמות המתבקשות.
לשם דוגמא, מי שחוכך בדעתו ומתלבט בנוגע לדרך השקעה מומלצת לחסכונותיו, כדאי שיקרא את פוסט ה"שוקולד המריר". זהו תיק השקעות שקול ומותאם היטב לחוסך הישראלי. מי שהיה עושה בו שימוש ב - 14 השנים האחרונות היה מגיע לתשואה שנתית גבוהה מ - 9% (החישוב הוא מינואר). זוהי תשואה טובה מרוב תשואות המשקיעים המקצועיים, ברמת סיכון נמוכה דרמטית.
לעומת זאת, בתחום החסכנות, או השלב המכונה "אין לי כסף, איך אני משיג עוד ממנו?", אני חושש שאין מנוס מלהתמקד בפרטים ולהבין מדוע יש עוד מקום להתפתחות לפני שמכריזים על שיטת ERE כמתאימה בישראל. לשם סיבור האוזן, הסולידית מציגה את יתרונות ישראל בכך שעלות ההשכלה והוצאות הבריאות בה נמוכות מבארה"ב. גיבורה של שיטת החסכנות של הסולידית (ג'ייקוב פיסקר) הוא דני, שחלק נכבד מהחסכון שלו הצטבר בזמן לימודיו בשווייץ ולפני גיל 30. לא בדיוק מדינות עם השכלה יקרה ובריאות יקרה, או גיל בו הוצאות הבריאות גבוהות. גם בארה"ב בה הוא חי, ישנם פתרונות שאינם קיימים בישראל. אני אשמח אם תספרו לי היכן ניתן לשכור קרוון למגורים בעלות נמוכה באיזור המרכז.
דוגמא נוספת היא המוחצנות עליה מדברת דורין. אני מקווה שקוראיה יסכימו שארה"ב מדינה מוחצנת יותר מישראל בתרבות הצריכה בה, אולם שם נראה כי קל הרבה יותר לחסוך. לכן איני יודע על מה מבוססת התורה.
כדי לספק קצת עניין לדיון, אני רוצה להציג את שיטת UERE, או Ultra Early Retirement Extreme.
יתרונות השיטה הן שהיא מותאמת היטב למציאות הישראלית, שהיא יעילה יותר כלכלית מ - ERE וגורמת לפחות בזבוז כלכלי. היא גם מתאימה היטב לעקרונות הסולידיים של מופנמות וצרכנות מינימלית.
אבל היתרון הבולט של השיטה הוא שהיא סופר פשוטה וניתן לתמצת אותה בשורה אחת:
אל תעזבו את בית ההורים.
אתם בטח זוכרים את התקופה ההיא לקראת סוף התיכון או אפילו כשהייתם סטודנטים. גרתם בבית ההורים, ולכן היו לכם הוצאות מועטות מאוד.
בפועל, חסכתם את הוצאות ה:
מגורים
מזון
תחבורה
תקשורת
ביגוד
וכנראה עוד הוצאות רבות.
מכיוון שזהו פוסט "פיננסי", ואנו עוסקים במתמטיקה, הרי שאם תעבדו בשכר מינימום בעבודה כלשהי, ייקל עליכם לחסוך 95% אחוז מהכנסתכם (או יותר), וכך תגיעו לעצמאות פיננסית תוך פחות משנתיים.
אם תשכילו להשקיע את הכספים שחסכתם, ותשארו לגור בבית הוריכם לנצח, הרי שתוכלו לפרוש לפני שבכלל תתחילו להרגיש את עול העבודה.
ביצוע השיטה קליל, כי אינו דורש מכם לבצע שינוי באורח חייכם - הרי כולנו ביצענו אותו, והוא לא יכביד על הוריכם כי הם כבר הצליחו לתמוך בכם כלכלית עד גיל 18, אז הם יכולים להמשיך.
השיטה הזו גם מונעת בזבוז, כי במרבית המקרים, כאשר ילד גדל ועוזב את הבית, הוריו לא משכירים את חדרו או עוברים לבית מגורים קטן יותר. הם בד"כ מחכים לא מעט שנים עד שיבצעו שינויים. בפועל, אתם עוזרים להוריכם לבזבז פחות כסף.
יש לה גם יתרונות רבים אחרים שלא אפרט כאן, אבל אני מקווה שהמסר העיקרי הועבר.
עקרון ה - One size fits all אינו פועל בדיאטות ובשיטות חסכון. הכללים והעקרונות בהם משתמשים צריכים להתאים לאדם שצריך לבצע אותם, ולשיטה הכלכלית במדינה. לדוגמא, חוקי מיסוי שונים והעובדה שבישראל מחוייבים לחסוך לפנסיה (כסף שיפגשו שוב רק אחרי גיל 60) שוברים חלק מעקרונות שיטת ERE.
כשחשבתי מה לכתוב בפוסט הזה, חשבתי שאכתוב על ההבדלים בין פיסיקה לפילוסופיה, שמתבטאים היטב בציטוט (שמיוחס בטעות לאיינשטיין):
In theory, there is no difference between theory and practice. But, in practice, there is.
אבל אני לא פיסיקאי, ואני מקווה שדורין לא פוצחת בקריירה של פילוסופית.
לבסוף החלטתי לנסות לסייע ולהרחיב את הדיון עוד, עד שנגיע לשיטת חסכון שתהיה מתאימה למרבית החוסכים הישראלים. החלטתי להציב ל"סולידית" אתגר. בהמשך יופיעו מספר שאלות שאני בטוח שהקוראים של הבלוג שלה ישמחו לקרוא את התשובות והפתרונות להן.
שאלות לדורין:
כמה זמן עבר מהיום שהתחלת לחסוך ועד שהגעת לעצמאות כלכלית? האם החסכון הזה בוצע בישראל, או משכר ממוצע ומטה היכן שבוצע?
ג'ייקוב פיסקר מתאר בפרוטרוט את המסע שערך מהיום שהתחיל ועד הגעתו לעצמאות כלכלית. הוא גם מספק בבלוג שלו שלל עדויות של אנשים אחרים שעברו דרך דומה והראו שהשיטה ניתנת לשכפול על-ידי אחרים, ולכן היא "אוניברסלית". האם תוכלי לספק או לתאר נסיונות דומים של אנשים בישראל?
בישראל 45% מהשכירים הרוויחו בשנת 2012 פחות מ - 5,200 ש"ח ברוטו בחודש ו - 70% הרוויחו פחות מ - 8,880 ש"ח ברוטו בחודש. ((הנתונים מלוח ה-9 של דוח מנהל הכנסות המדינה)) האם תוכלי לבנות עבורם תקציב חודשי שיאפשר חסכון של 75% מההכנסה שלהם נטו?
אני מאמין שניתן לספק תשובות לכל השאלות האלו. ושמהן תתברר הסיבה לקושי בחסכון בישראל.